This website is no longer maintained. Its content may be obsolete. Please visit http://home.cern/ for current CERN information.
Michel Goossens IT/ASD
If you are a regular visitor of W3C's (World Wide Web Consortium) web page, you will have seen that in recent months many of the initiatives I mentioned in my CNL 227 article Hyper-activity in the Web-world have seen a lot of progress. In this article I want to go into some detail about the most important points.
|
Please note that all Web activity at CERN is governed by the Web Policy
Group (WPG) and the Divisional Webmasters Group (DWG). The Web Office
coordinates the day-to-day tasks. The DWG provides Guidelines for Web
sites at CERN; when in doubt, consult your Division's responsible member.
Revelant URLs:
WPG:
|
The reason why HTML is so popular has much to do with its intrinsic simplicity (it is so easy to learn), but also because of the many non-standard extensions which are offered by the various browser vendors to help users to make their pages look professional and attractive. However, this tower of Babel of incompatible extensions is a real threat to the integrity of the Web, since it kills the universal availability of the information.
Most people love HTML because it is a clean little language that they can master in an afternoon. It is universal and should run everywhere. In the real world one is often confronted with broken links and a lack of portable ways to format the information. Many of us have had to (mis)use tables, frames, Java and other scripts to get a representation we like, due to the lack of a real tool to craft universally displayable Web pages.
It is probably worthwhile to look at the problem areas where we think HTML should be improved.
Recent work has tried to address one or more of these problems. One approach was to increase the functionality of HTML, and therefore HTML 4 was developed. To better separate form and content the style sheet language CSS (Cascading Style Sheets) standard was recommended. The XML (Extensible Markup Language) effort deals with application-specificity and better data organisation. Dynamic HTML (DHTML) goes some way towards adding a dynamic representation to Web pages. In that context DOM (Document Object Model) is bound to play an important role by allowing programs to access HTML (XML) elements as a structured collection of object data, each having a set of properties and methods. We shall look at some of these developments below. One must bear in mind, however, that very few browsers, if any, support these new features at present. Nevertheless it is important that users of the Web (aren't we all?) are kept informed about this evolution and have some idea of what will become available in six month to one year. This will allow us to better plan for the future and not invest unnecessarily in techniques which will be deprecated or replaced before long.
On the 18th of December 1997 W3C issued HTML 4.0 as a W3C Recommendation, which means that HTML documents should henceforth be marked up according to that specification (the full document is over 360 pages and is also available as PostScript or PDF files). The more significant changes with respect to the previous version 3.2, which was released in January 1997, are listed below.
<H2 id="mysect">This is a uniquely identified section heading. < id="mypara">This is my addressable paragraph. ... <P>As stated in a <A HREF="mypara">paragraph</A> which was part of a <A HREF="mysect">section</A>...
<P> <!-- First, try the Python applet -->
<OBJECT title="Electrons going round and round"
classid="http://www.cern.xxx/CirculatingElectrons.py">
<!-- Else, try the MPEG video -->
<OBJECT data="CirculatingElectrons.mpeg" type="application/mpeg">
<!-- Else, try the GIF image -->
<OBJECT data="CirculatingElectrons.gif" type="image/gif">
<!-- Else render the text -->
Electrons circulating in the LEP tunnel.
</OBJECT>
</OBJECT>
</OBJECT>
The <OBJECT> element replaces (and thus deprecates) tags like <APPLET> and <IMAGE>. Below are a few examples of use.
<P><OBJECT declare
id="electron.declaration"
data="CirculatingElectrons.mpeg"
type="application/mpeg">
Electrons circulating in the LEP tunnel.
</OBJECT>
...
<P>A nice <A href="#electron.declaration">
animation of electrons in LEP.</A>
<P><OBJECT codetype="application/java"
classid="AudioItem"
width="20" height="20">
<PARAM name="snd" value="Greetings.au">
Java applet that greets the user.
</OBJECT>
...text before... <OBJECT data="myfile.html"> Warning: The file "myfile.html" is not available for embedding. </OBJECT> ...text after...
Today, most documents on the Web are still marked up using the HTML 3.2 DTD and no browsers fully support HTML 4 as yet (Netscape 4 and MS Internet Explorer 4 do already a good job). To benefit fully of the possibilities of HTML 4 one also needs support of Cascading Style sheets (CSS Version 1), and here also browsers still do not fully conform.
Even though HTML 4 is without doubt a step in the right direction if one wants to support the Web in a standard way, it is still too limited and above all too static to cope with all of the Web's many application areas (databases, search engines, optimal presentation, professional printing, data verification). A new technology had thus to be introduced to do away with the limitations related to HTML's unalterable DTD. XML (for Extensible Markup Language) is the answer.
After some one year and a half of work in the framework of the W3C SGML working group, the W3C issued XML 1.0 as a Recommendation on the 10th of February 1998. It is the first in a suite of standards which will revolutionise information handling on the Web.
XML is, by design, a subset of SGML (Standard Generalized Markup Language, defined as ISO standard 8879 in 1986). SGML's scope is very broad and the language rather complex (both to learn and implement). The W3C recognised this fact and decided to develop a light-weight version, XML, which does away with SGML's rarely used and more complex features. It is said sometimes that XML offers about 90% of SGML's functionality at some 10% of its complexity, thus making sure that the Ten commandments of XML (its design goals as specified by the W3C SGML Special Interest Group when they started their activities), were fulfilled. These goals stated that XML should be straightforward to use on the Internet, allow easy processing of XML documents (i.e., XML parsers should be easy to write), and that the number of optional features should ideally be zero. Moreover, they wanted XML to be easy to learn, and XML documents straightforward to create and modify. XML makes it easy to declare the structure of a document by decomposing it into logical elements. All possible relations between these elements are described in a DTD (Document Type Definition). Several applications of XML are being defined by W3C. Amongst them are XLL (eXtensible Linking Language), XSL (eXtensible Style Language), and MML (Mathematical Markup Language). At the same time a coherent data model (XML-DATA) is also being discussed. It introduces an object data model which makes it possible, for instance, to express the DTD using an XML syntax.
As already mentioned, each element of an XML document has to be declared in a DTD, which provides a formal definition for the XML language instance for the document class being considered. This allows XML parsers to check the validity of document instances marked up according to that DTD, verifying, for instance, the correct nesting levels, whether all document components have been defined, etc. Note, however, that strictly speaking, the XML does not require that a DTD be present. For instance, for browsers, it could be too time-consuming for each document to download and parse a DTD and check the document against this DTD. XML applications should make sure that all documents at creation time adhere to a DTD, so that browsers can assume that they are correct. In this case XML only wants the document to be well formed, and it will be up to the browser to give default interpretations for undeclared elements.
XML is based on the concept of documents composed of a series of entities (nowadays we would probably prefer to talk of objects). Each entity contains one or more elements, and each element can be characterised by zero or more attributes (properties) that describe the way in which it is to be processed. The relationships between elements and the list of their possible attributes is specified in the DTD.
The beauty of XML (SGML) is that using this mechanism of defining a language with a DTD, each institute, group, company, organisation, etc., can define its own language for all the different kinds of document they have to handle. By being able to choose user-friendly markup tags, adapted to a particular application domain or cultural environment, the use of these tags will be much easier to comprehend and the markup error rate will be substantially lower than when using a more generic markup scheme. Moreover, with the help of intelligent editors, that will hide the markup or else guide the user by only allowing tags possible in the current context, it will be trivial to compose syntactically correct documents.
With XML the syntax for tags and entity references (a way of including
foreign components) is fixed. Elements and their attributes are
entered between matched pairs of angle brackets
(<...>) while entity references start with an
ampersand and end with a semicolon (&...;).
Comments are specified between <!-- ... -->.
An example is the following trivial XML document.
<coolxml>XML is a cool idea!</coolxml>
This XML document cannot, as such, be validated, since no DTD is specified. It is, however, well-formed and complete.
If we want to become a little more ambitious, we could try and define a language to compose texts for sending invitations to our friends. We could envisage something like the following.
<invitation> <to>Anna, Bernard, Didier, Johanna</to> <date>Next Friday Evening at 8 pm</date> <where>The Web Cafe</where> <why>My first XML baby</why> <par> I would like to invite you all to celebrate the birth of Invitation, my first XML document child. </par> <par> Please do your best to come and join me next Friday evening. And, do not forget to bring your friends. </par> <par> I really look forward to see you soon! </par> <signature>Michel</signature> </invitation>
This document is clearly marked up. All elements are delimited by
start and end tags (like <date> and
</date>, respectively) and they are properly
nested. There also exists an outermost root element, which
appears only here and not as contents of any other element. We say
that our document is well-formed. Such a document is easy to
parse with a computer, one of the design aims of XML. There is,
however, at least one shortcoming to this document, namely that its
structure is hard to guess. We have merely indicated the semantic
function of a few text strings, but it is not clear what the relation
between the various document components is.
To clarify the relation between the various document elements we
decide to subdivide our document onto three parts: front,
body, and back, corresponding to the
introductory information, the message text itself, and the closing
part, respectively. We also thought it would be appropriate to
emphasise a few words in the text by bracketing them with
<emph>...</emph> tags. A few comment lines
were added as well.
<invitation> <!-- ++++ The header part of the document ++++ --> <front> <to>Anna, Bernard, Didier, Johanna</to> <date>Next Friday Evening at 8 pm</date> <where>The Web Cafe</where> <why>My first XML baby</why> </front> <!-- +++++ The main part of the document +++++ --> <body> <para> I would like to invite you all to celebrate the birth of <emph>Invitation</emph>, my first XML document child. </para> <para> Please do your best to come and join me next Friday evening. And, do not forget to bring your friends. </para> <para> I <emph>really</emph> look forward to see you soon! </para> </body> <!-- +++ The closing part of the document ++++ --> <back> <signature>Michel</signature> </back> </invitation>
It is important to note that up to now we have said nothing about how this document should be rendered. The XML instance shown above only describes the information and how its various structural elements are related. How an XML application handles these data is not specified. One must define a transformation of the various elements to an output format (via a style language, such as XSL, see below) to be able to view, print, or otherwise represent or exploit the information.
In the example above we introduced a little language to allow us to mark up invitations in a convenient, clear, and easily processable way. If we want XML applications to validate documents which we are going to write according to that specification, we have to formally define our language. As explained earlier, this is done with the help of the Document Type Definition (DTD). The DTD formally defines the grammar of your little language, in other words it describes the structural relationship between the elements and their possible attributes. In the case of our invitation language, we could define the following DTD.
<!DOCTYPE invitation [ <!ELEMENT invitation (front, body, back) > <!ELEMENT front (to, date, where, why?) > <!ELEMENT date (#PCDATA) > <!ELEMENT to (#PCDATA) > <!ELEMENT where (#PCDATA) > <!ELEMENT why (#PCDATA) > <!ELEMENT body (par+) > <!ELEMENT par (#PCDATA|emph)* > <!ELEMENT emph (#PCDATA) > <!ELEMENT back (signature) > <!ELEMENT signature (#PCDATA) > ]>
This model tells the computer that an invitation always has
three parts: front followed by body, and
terminated by back. The front part is a
sequence of from, to, where
and, optionally, why elements. The fact that the
why element is optional is signalled by the presence of
the ? sign. The central body part of the
invitation consists of one or more paragraphs (the sign +
means one or more, while * means zero or
more). They are enclosed inside <par> and
</par> tags and can themselves include
#PCDATA (see below) or emphasised text (flagged with
<emph> tags). Finally, the back part
only has a signature element. Each of the final nodes of
the document structural tree can contain parsed character
data (#PCDATA). Such data are analysed (parsed) by
the XML application and validated to see whether all references are
known.
XML has some quite large differences from HTML (and from most of the
other current SGML applications). First, all element and attribute
names are case sensitive, meaning that <par>,
<Par>, and <PAR> are
different elements. Second, all elements must be completely
specified (i.e., begin and and tags must always be used). A
sort of corollary of this statement is that empty elements
are noted in a special way (since they have no content). Consider,
for instance, that you would like to add an image to your content
model. You would declare it as empty, and could choose a tag name like
<image/> (note the / at the
end of the tag). We, of course, would have to anchor this
element in the relevant place in our DTD, for instance,
<!ELEMENT body (par|image)+ > <!ELEMENT image EMPTY >
One can associate supplementary information about an element by using
attributes. They specify which properties can be applied to a
given element. As an example let us consider the why
element, and assume that we want to offer several ways for typesetting
the text. We could define attributes type and
col as follows:
<!ATTLIST why type (bold|slanted|upright) "upright" > <!ATTLIST why col (red|green|blue|black) "black" >
These statement inform the XML system that the start-tag
<why> can contain type and
col specifiers. Then we could set the why
text in a different type and/or colour, for instance,
<why type="slanted" col="red">Text is slanted and in red</why>
The application should associate the slanted value of
the type attribute with a slanted typeface and the
red value of the col attribute with
red ink. It is the task of the style language to make these
associations explicit. When specifying the list of possible attribute
values with the <!ATTLIST ...> tag, we also
indicated at the end which is the default value, i.e., the type and
colour to be used when no attribute is specified explicitly on the
<why> start tag. In other words, the following four
lines are equivalent.
<why>Normal black text</why> <why type="upright">Normal black text</why> <why col="black">Normal black text</why> <why type="upright" col="black">Normal black text</why>
Foreign material (text fragments, special characters, images,
external files) can be included in an XML source using the
<!ENTITY ... > declaration. XML distinguishes two
types of entities: internal and external.
An internal entity has its value specified inside the document declaration and has no separate associated storage object. All internal entities are parsed. They are used for various purposes, which are detailed below.
<!ENTITY MML "Mathematical Markup Language">
<!ENTITY gt CDATA ">">XML predefines five entities:
lt (<), gt
(>), amp (&), apos ('), and
quot (").
<!ENTITY % list "UL | OL | DIR | MENU">
All internal entities must be declared in the DTD or in the document
type declaration in the prolog part of the document instance. In any
case, entity references should follow their declaration in the
source. A general entity reference has the name of the entity
preceded by an ampersand (&) and followed by a semicolon
(;). On the other hand parameter entity references are
indicated with the % (instead of the &)
character, and can only occur inside the DTD, e.g.,
%list; will expand to the content model shown above.
An entity reference triggers the substitution, at the given point in
the XML source file, of the entity reference by its contents.
For instance, with the definition given above, entering
&MML; in a source file would expand into the string
Mathematical Markup Language. Entity definitions can
themselves refer to other internal and already defined entities, for
instance,
<!ENTITY XMLS "&MML; and other extensible languages">
External entities are all those that are not internal.
They are used to reference data external to the given document
instance. Data included via such an entity reference can either be
parsed or declared with the NDATA keyword, in which case
the data remain unparsed (e.g., a bitmap image or binary file).
Possible forms are the following.
"SYSTEM", and followed by a URI (Universal
Resource Identifier). For instance, on UNIX
we could define an entity with the following definition.
<!ENTITY article SYSTEM "/usr/goossens/articles/xmlart.xml">In an XML source file the contents of the file at the given URI can then be included (and parsed) with an entity reference of the form
&article;
"PUBLIC", followed by a public identifier
literal, itself followed by a system literal in the form of a URI.
<!ENTITY % html4-strict PUBLIC "-//W3C//DTD HTML 4.0//EN"
"http://www.w3.org/TR/REC-html40/strict.dtd">
In this case we define a (parameter) entity which is known by the
public name -//W3C//DTD HTML 4.0//EN, and from this the
XML application can try and build a URI pointing to a file (for
instance, using the catalog file proposed by the SGML-Open
consortium). If such a URI cannot be generated, the external entity
reference will be resolved by using the explicit URI specified at the
end.
<!ENTITY xmlfig1 SYSTEM "http://www.myserver.edu/book-files/figures/xmlfig1" NDATA GIF >Here we define a GIF image that is present on a Web server and can be included with the entity reference &xmlfig1;. The XML application parsing the document containing this entity reference must know how to handle GIF images. This is declared with the
<!NOTATION ... > tag, which specifies which
program module must be called for a given notation. On Windows one
could do this as follows.
<!NOTATION GIF SYSTEM "c:\Program Files\Internet Explorer\Ie4.dll" >
For increase the readability of documents by humans it is convenient
in many cases to add blank lines or spaces. Most of the time this
white space is not significant and is not intended for inclusion in
the output instance of the document generated by the XML
application. Sometimes, however, white space should be preserved in
the output representation (for instance when displaying computer
computer code). To signal the fact that white space should be
preserved as-is, a special reserved attribute,
xml:space should be associated with the
element in question, for instance,
<!ELEMENT computercode (#PCDATA) > <!ATTLIST computercode xml:space #FIXED "preserve" >
Source material part of a computercode element will
preserve its line breaks, tabs, etc., whereas by default most XML
applications will fold them into spaces when outputting the
contents of an element.
XML documents consist of three logical types of markup. An example is shown below.
<?xml version="1.0"?> <!-- XML PI --> <!DOCTYPE coolxml [ <!-- DTD internal subset --> <!ELEMENT coolxml (#PCDATA)> ]> <!-- Document instance --> <coolxml>XML is a cool idea!</coolxml>
latin
1, and is self-contained, so we could also have specified:
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes">
<!DOCTYPE memo SYSTEM "~/sgml/dtds/memo.dtd">Both internal and external subsets can be present (one can, for instance, in the internal subset add attributes to elements defined in the external subset with
<!ATTLIST...> declarations
and define supplementary entities with <!ENTITY...>
declarations).
coolxml in the example above, or
invitation in the example in the preceding sections).
A document is called valid if all three components are specified and when the document instance conforms to the rules defined in the document type definition. As explained previously, a document can also be well-formed. In this case only the document instance need be present (no formal checking can thus be performed), a root element should enclose all the rest and the nesting of elements should be correct.
Adobe is implementing support for XML in both FrameMaker and FrameMaker+SGML, expecting to ship the XML-enabled versions in the second quarter of this year.
Microsoft Internet Explorer 4 is very active in the XML effort. At
present you can download from the Microsoft Web site a number of
tools, including msxml, a validating XML parser written in Java. It
checks for well-formed documents and optionally permits checking for
validity. Once parsed, the document is exposed as a tree through a set
of Java methods, which support reading and writing XML structures.
As an example of the use the msxml parser let us take our
coolxml mini document and ask the program to display a
tree representation of the document instance. The command used and the
generated output is shown below (jview, a Java
command-line loader for Windows 95/NT, is used to load the
msxml class library).
>jview /cp:p d:\msxml /cp:a d:\msxml\classes msxml -d1 cool.xml DOCUMENT |---PI xml "" |---WHITESPACE 0x20 |---COMMENT -- | +---CDATA " XML PI " |---WHITESPACE 0xa |---DOCTYPE NAME="coolxml" | |---WHITESPACE 0x20 0xa | |---COMMENT -- | | +---CDATA " DTD internal subset " | |---WHITESPACE 0xa 0x20 0x20 | +---ELEMENTDECL coolxml (#PCDATA)* |---WHITESPACE 0xa |---COMMENT -- | +---CDATA " Document instance " |---WHITESPACE 0xa |---ELEMENT coolxml | +---PCDATA "XML is a cool idea!" +---WHITESPACE 0xa
Other XML parsers are available. However, James Clark's Jade/SP system SGML/DSSSL system is remarkable in that it works on almost all computer platforms and provides an efficient tool to treat SGML (XML), and generate HTML, TeX, and RTF output via DSSSL style sheets.
Grif's Symposia, an HTML browser and editor, is being rewritten as Symposia doc+, a complete Intranet publishing tool. It comes with a WYSIWYG-type authoring tool, a database publishing mode, and a graphical site manager. A free evaluation copy is available on the GRIF web site.
In this section we shall look at two other components of the XML effort, the Extensible Style Language (XSL), and the Extensible Link Language (XLL).
As explained before, an XML application does not know, from the markup itself, how to render a document on a output device. To also standardise within the XML context the way a document should be rendered the Extensible Style Language has been defined. Historically two style languages existed before the XSL effort got underway. DSSSL (Document Style Semantics and Specification Language) has a Scheme-based formalism which allows transformations between document types and complex output specifications for preparing all kinds of output formats, including table of contents, indexes, page headers, floats, etc. CSS (Cascading Style Sheets) is a W3C recommendation. It targets mainly Web-based applications, which do not need the full DSSSL machinery. Recognising this fact, the XML working group is basing XSL on a subset of DSSSL (DSSSL-O) and full CSS, allowing the basic flow objects of both to be used. The XSL Proposal states that XSL should have the following capabilities:
XSL uses a declarative syntax to deal with the rendering of most tags.
When needed, scripts (written in ECMAscript, a standarized version of
JavaScript) can handle complex tasks. Today the development of XSL
is still ongoing. Pre-releases of software interpreting XSL
stylesheets exist in the form of Henry Thompson's xslj
program, which translates from XSL into extended DSSSL, which can then
be interpreted by James Clark's jade program, which
interprets DSSSL and has formatting back-ends for RTF, TeX, SGML, and
HTML with CSS. On the other hand, Microsoft has an XSL processor
msxsl which can be used on the command line to generate
HTML output from an XML document and an XSL stylesheet (in this case
only CSS flow objects are supported and the processor only runs on
Windows 95/NT).
As an example of how one might use XML and XSL let us take our
invitation document and parse it with James Clark's
jade to try and get some output. First we have to write
an XSL style to define how we want to translate the document's
elements into output stream flow objects. An excerpt of that file,
giving a idea of the look and feel of XSL, is shown below:
<?XML version='1.0'>
<!DOCTYPE xsl SYSTEM "xsl.dtd">
<xsl>
<define-script>
var FontSize=12pt;
</define-script>
<!-- set global page dimensions -->
<rule>
<root/>
<simple-page-sequence
page-width="205mm"
left-margin="25mm"
right-margin="25mm">
<scroll
font-size="=FontSize"
line-spacing="=FontSize">
<children/>
</scroll>
</simple-page-sequence>
</rule>
<rule>
<element type="front">
<target-element type="date"/>
</element>
<paragraph>
<literal>When: </literal>
<children/>
</paragraph>
</rule>
....
<style-rule>
<target-element type="emph"/>
<apply font-posture="italic"/>
</style-rule>
</xsl>
We remark first that the markup uses the XML language, and is
characterised by a DTD xsl.dtd, which defines all the
elements present in the XSL style language. We use various tags, like
<define-script>, for variable declarations and
function definitions, and <rule>,
which has both a pattern to define the source element to which
the rule applies, and an action which specifies the (DSSSL-O
or CSS) flow element to construct. The first rule in the example
applies to root element (the document as a whole) and
sets page dimensions and typographic quantities, such as the default
font size. The second rule applies to the date element
inside a front element. The action to take is to start a
paragraph, output the literal string When: , and then
handle the children (enclosed elements) of the current
element. Finally, we see a <style-rule> tag, which
associates flow object characteristics with XML elements
(they do not create such flow objects). For instance, the
emph element is associated with an italic typeface, but
we could as well have decided to make emphasised text bold, or red, or
whatever.
As the jade translator only handles the DSSSL style
language, we first have to use Henry Thompson's xslj
program to translate our XSL code into extended DSSSL, which can then
be interpreted by jade. We used that program to obtain an
HTML and TeX representation of our text. The results are shown for
HTML (via a CSS style sheet) with MS Internet Explorer and Netscape
below.
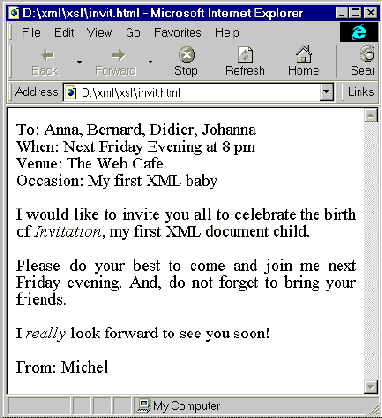 |
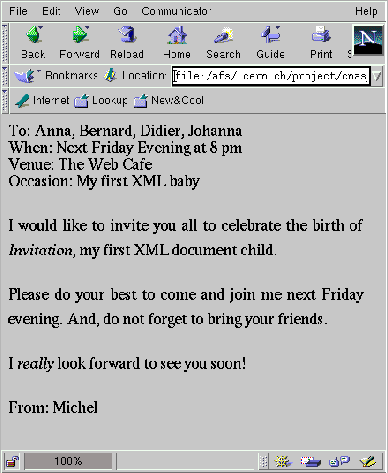 |
The output for TeX obtained with Sebastian Rahtz' jadetex
package looks as follows (remember we used a rather trivial XSL style
file).

XML's Extensible Link Language will, of course, still support simple links as they exist in HTML for the Web today. However, building on experience gained with HyTime (ISO/IEC 10744) and the TEI (Text Encoding Initiative) the document linking facilities of XML are vastly improved with the introduction of extended links, Xlinks and link groups as shown in the following image.
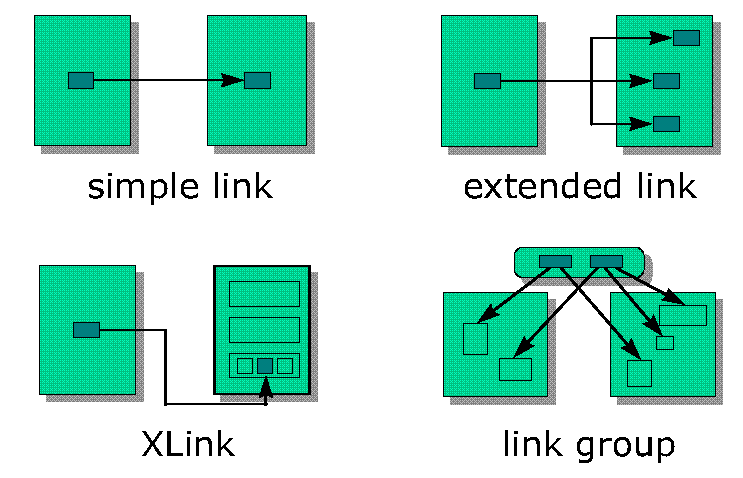
In his seminal Internet paper XML, Java, and the future of the Web Bosak explains that XML should implement and provide a standard syntax for all classic hypertext linking mechanisms, such as
Below we give a list of a few of the more important initiatives and markup languages which decided to use XML.