This website is no longer maintained. Its content may be obsolete. Please visit http://home.cern/ for current CERN information.
|
|
| Previous: | The Learning Zone | (See printing version) | |
| Next: | User Customization of Apache Web Servers |
Mikhail Ranish
, (ranish@intercom.com)
Note: this article is a reproduction of the
"Partitioning Primer" written by Mikhail Ranish in his more
detailed
"Partition Manager" Home page. This provides a detailed
description of the hard disk technology, evolution and management
on the PCs. It also explains the terminology used in this technical
domain.
A French version of this "Partitioning Primer" ("Les bases du
partitionnement") is also available on the Web.).
First disks had a simple design. They had one or more rotating platters and a moving arm with read/write heads attached to it - one head on each side of the platter. The arm could move and stop at the certain number of positions. When it stopped each head could read or write data on the underlying track. Every read or write had to be done in blocks of bytes, called sectors. Sectors were usually 512 bytes long and there were a fixed number of sectors on each track.
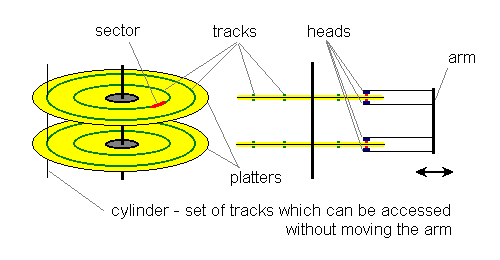
The drives themself did not have much electronics and had to be controlled by the CPU for every single step. First the CPU had to issue a command to position the arm. Then it had to instruct the drive which head should perform read and from which sector. After that the CPU waited until the desired sector was moving under the head and then started data transfer. This design was relatively simple and inexpensive, but there were several disadvantages.
First of all, each Input/Output operation involved a lot of CPU activity. Also, the disk surface was used inefficiently. It was convenient for the programmers to have a fixed number of sectors on each track, but it was a waste of space, because the longer outer tracks could hold much more data than the shorter inner ones. Later, when digital electronics became cheap, hardware engineers could resolve this problem.
When IDE (Integrated Drive Electronics) disks came out they had a small processor on each drive. This helped to free up CPU time by implementing a more sophisticated set of commands. The disk space was also used more efficiently. Engineers had placed more sectors on the outer tracks, but still provided software writers with a convenient "cubical" look of the disk by doing internal translation of CHS (Cylinders, Heads, Sectors). For example, my old 340M disk has only two platters = 4 heads (sides), but it reports 665 cylinders, 16 heads (sides), and 63 sectors. In reality it, probably, has more then 4*63 sectors on each outer track and a little less than 4*63 on the most inner tracks, but we could not know for sure.
With the IDE disks the CPU only has to inform the CHS of the sector that it wants to read and the drive's electronics will position the heads and call back the CPU when it is ready to start data transfer.
The newest drives have an even simpler interface. Instead of addressing sectors by their CHS (Cylinder, Head, Sector) address they use LBA (Logical Block Addressing) mode. In LBA mode a program has to specify only the number of the sector from the beginning of the disk (all sectors on disk are numbered 0, 1, 2, 3, ... ). In addition, new disks have internal buffers, where they can store many sectors. This can speed up disk access a lot, because they can read data into a buffer using all four heads at the same time.
Virtually all modern Operating Systems use LBA addressing, but the CHS notation is still around. Most importantly, MS-DOS, which is almost 20 years old, uses only CHS. Also some programs, like Partition Magic, would not work if partitions did not start at a cylinder or a side boundary. Finally, it is easier to talk about hundreds of cylinders than about millions of sectors. Therefore, we will be using CHS notation throughout this discussion.
There are several things to note about CHS addressing. Suppose that we have a 340M disk with 665 cylinders, 16 heads, and 63 sectors per track, then the legal values for cylinder numbers are 0..664, for head (side) 0..15, and for sector 1..63. The maximum allowable values for CHS addressing mode are 0..1023, 0..255 and 1..63 for cylinders, heads, and sectors respectively. Multiplying out these values shows that the largest hard disk that could be addressed with CHS is 8G. Therefore, if a disk holds 12G many programs will see only 8G because they use CHS.
All hard disks on all IBM compatible computers have the same way of partitioning. The first sector of the disk, called the MBR (Master Boot Record), contains the partition table. This table has four records, each of which can describe one partition. In the simplest case we would have all disk space assigned to one partition, as in the following example:
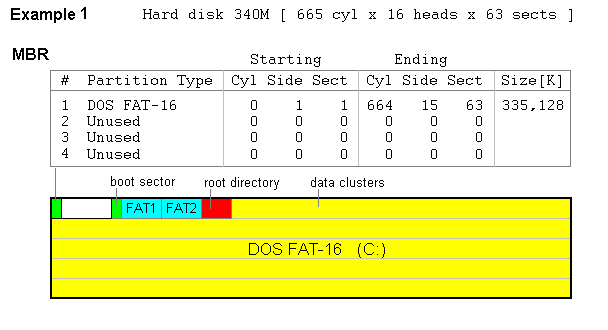
Note that the MBR occupies one sector at cylinder 0, side 0, sector 1 and the partition starts on the cylinder 0, side 1, sector 1. The 62 sector gap between them was left unused, because we want all partitions to start at the cylinder boundary or, at least, on the side boundary. This is not required with LBA, but we need to follow this rule in order to satisfy old software (for instance MS-DOS).
Another important point to be made is that the Operating System and the File System are different things, which many people use interchangeably. The Operating System (OS) is a piece of software which controls CPU and lets different application programs run on the computer and use different system resources. The File System is a way to organize files and directories on the hard disk. The confusion comes because every good Operating System has one or more File Systems and they become closely associated.
In our example all we know is that we have a FAT-16 File System. We have no idea which Operating System is installed on it. It could be MS-DOS 6.22, it could be Windows 95 or NT, or it could be all the three installed in different directories in the same partition. If we put additional effort we could even install Linux there (but it is usually better to have different Operating Systems installed in separate partitions).
Another reason to have multiple partitions is the security against computer crashes. For example, if the system crashes in such a way that the FAT table get corrupted, access to all your files will be lost, because the FAT table tells where each file is located on the disk. The FAT table is so important that it was decided to keep two copies of it at the beginning of the disk. For very valuable files, it might even be wise to create a second partition (then it will have its own FAT) and keep copies of important files there.
However, do not rush to create a second partition. First of all, experience shows that 99% of errors damage only one copy of the FAT. Secondly, for the majority of users, it would be sufficient to copy personal work to a floppy disk once a week and keep it in the safe place. So, in the case of a crash, the user would only have to reformat the disk and reinstall all programs.
Now, regardless of the reason, let us see what happens if we have multiple partitions.
In the second example
we have two partitions with the FAT-16 File System. For some reason
the creators of DOS decided that a second or third FAT partition
must be put not in the MBR but into the Extended DOS
partition. This extended partition appears like an ordinary
partition in the MBR (it occupies space) and inside it has a table
similar to partition table in the MBR, called the EMBR
(Extended MBR), which lists partititions enclosed in
the extended partition. Inside the extended partition there can be
one more FAT partitions and the reference to the next extended
partition, then another FAT, and so on, as long as these are drive
letters for them (D:, E:, F:, ... ). All those
partitions have special name logical drives, contrary
to the first FAT partition C:, listed in the MBR,
which is the primary partition.
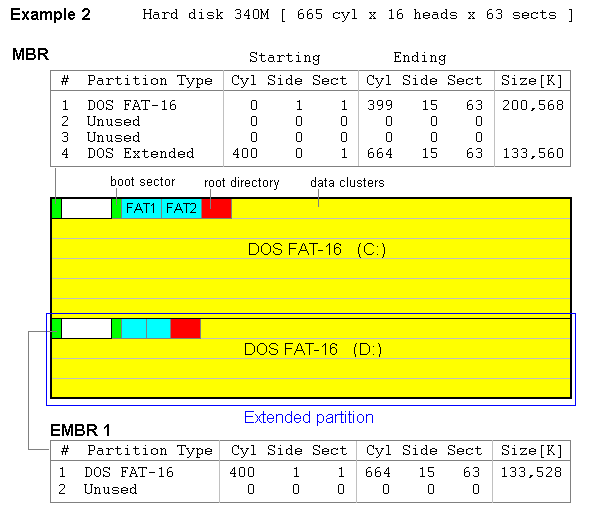
We can only speculate on the reasons for choosing such a design, but there are two very obvious ones. The first one is that the partition table has only four records, so that one cannot have more than four partitions without having extended partitions. To understand the second reason you have to know that, according to Microsoft, these can only be one primary partition on the disk and you cannot boot from the logical drives, which means that you cannot have more than one DOS-like Operating System on the computer (a way to cut off the competitors). In reality, these can be more than one primary FAT partition and we will see later how to do that.
Also, note that the
FAT table in the second partition is smaller than in the first one.
It obviously happens because the second partition is smaller. The
FAT table has one entry for each cluster in the partition - it
contains the number of the next cluster in the chain. There is one
chain of clusters for each file. The number of the first cluster of
the file is stored in the directory entry for that file, along with
the file size, some attributes, and the last modification date.
Space for the directories other than root is allocated
among the data clusters, just as if they were ordinary files. Only
the root directory has a special location.
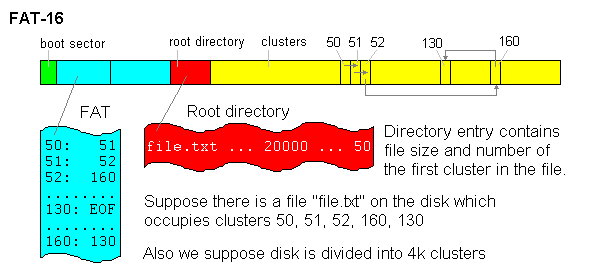
The name of the File System is FAT-16 because it has a FAT (File Allocation Table) and also because each entry in FAT is 16-bits long (2 bytes). This means that the FAT-16 partition cannot have more than 65,535 clusters (216 = 65,536). Similarly FAT-32 has 32-bit entries and could address up to 232 clusters. (Actually they use only 28 bits). Based on that we can calculate the maximum partition sizes for FAT File Systems. Here is the table:
| Cluster
size |
File System type | ||
| FAT-12 | FAT-16 | FAT-32 | |
| 2K | 8M | 128M | 512G |
| 4K | 16M | 256M | 1024G |
| 8K | 32M | 512M | 2048G |
| 16K | 64M | 1G | 2048G |
| 32K | 128M | 2G | 2048G |
| Partition size | Recommended File System / cluster size |
| 1-16M | FAT-12 / 4K |
| 16-256M | FAT-16 / 4K |
| 256-512M | FAT-16 / 8K |
| 512M-1G | FAT-16 / 16K or FAT-32 / 4K |
| 1-8G | FAT-32 / 4K |
| 8G and up | FAT-32 / 8K |
The next example shows the co-existence of DOS and Linux on the same disk and some more insights into the structure of the extended partition.

First of all, this configuration could be derived from Example 2 if we shrink both FAT partitions and then install Linux. Also, the Linux native File System uses a different way of organizing files than does the FAT File System. The main structure is called the i-node table. There is one i-node allocated for each file. The i-node keeps a note of file size, attributes and file creation, last modification, and last access times. Unlike FAT, File System directories have only file names and i-node numbers. The space allocation also differs from FAT, but it is out of the scope of this discussion.
A careful study of cylinder numbers in the third example shows that the extended partition has three EMBR tables. Each one is stored at the beginning of the extended partition and keeps a record about FAT (or other) partitions and the pointer to the next extended partition. Note that the first extended partition includes all FAT and extended partitions, but all other extended partitions (level 2, 3, ... ) include only one data partition.
Finally, it is important
to mention that this partitioning scheme has some drawbacks. First
of all, the Linux swap partition is located at the end
of the disk, far from the Linux root
partition. It turns out that disk heads move back and forth
between them all the time, decreasing system performance. It is
much better to place the swap partition as close as possible to the
partition where the OS is installed. Also, some people think that
if they put the Windows swap file into the separate
partition the computer will work faster. This is true only if that
partition is located on a separate hard drive, which is
as fast as or faster than the first one. Placing the swap file on the old slow
drive will not do any good. It is much better to set in the Control
Panel a fixed size for the swap file, equal to the amount of RAM,
and to place it on C:. Then you can run a program like
Norton Speed Disk which will optimize the swap file.
For matters related to this article please contact the author.
Cnl.Editor@cern.ch