   |  |
Computing Technical Design Report
| | |
Computing Technical Design Report
At the time of writing ATLAS has recently begun development of the final distributed data management (DDM) system for startup, DonQuijote 2 (DQ2). The scope of the system encompasses the management of file-based data of all types (event data, conditions data, user-defined file sets containing files of any type). The requirements, design and development of the system draw heavily on the 2004 Data Challenge 2 experience gained with the ATLAS-developed DonQuijote distributed data manager (DQ) and the Grid middleware components underlying it. The other principal input is the ATLAS Computing Model, which provides a broad view of the environment and parameters the DDM system must support. The overall objective for DQ2 is to put in place as quickly as possible a highly capable and scalable system that can go into production as soon as possible, and which can be incrementally refined through real usage to be ready for computing system commissioning and data taking. During 2005 it will support steady-state production, increasing analysis activity, the onset of commissioning, and preparatory testing on the Service Challenge 3 (SC3) service in advance of the computing-system-commissioning scalability tests (DC3) coming in early 2006. A high-level timeline for DQ2 development can be found in Section 4.6.8 .
DQ2 carries over the basic DQ approach of layering a stable and uniform experiment-specific system over a foundation of third-party software (Grid middleware, common projects) while making many changes at all levels from design precepts to implementation. The approach is well suited to supporting our multiplicity of Grids; accommodating a time-varying mix of middleware as components mature; and integrating pragmatic in-house developments that provide experiment specificity and fill gaps in the available middleware. The present DQ consists of three main components: a uniform replica catalogue interface fronting Grid-specific replica-catalogue implementations; a reliable file-transfer service utilizing a MySQL database to manage transfers using gridftp and SRM; and Python client tools for file lookup and replication. Further information on DQ can be found at ref.[4-13].
Continuity in meeting data management needs during DQ2 development is being provided by sustaining support and essential development of DQ until a transition to the fully-deployed production DQ2 is completed in late 2005.
The next subsection summarizes the DC2 experiences that to a great extent underly the design and implementation decisions taken with DQ2. The rest of the section focuses on DQ2: design precepts and requirements; scenarios and use cases; system architecture; implementation and evolution; and development, deployment and operations planning and organization. The DQ2 system design is based on an analysis (following the Computing Model) of data management in ATLAS including managed production, global data discovery, managed distribution operations, and end-user analysis support including `off-Grid' usages.
During DC2 a number of data-management shortcomings were found, many originating in problems with or shortcomings of the Grid middleware. Grid replica catalogues were a principal source of problems. The catalogues from the middleware providers of the regional Grids were adopted and used "as-is" by ATLAS. The granularity at which the catalogues operated (individual files) and the functionality provided (simple inserts, updates and queries) proved to be insufficient. Bulk operations were needed for realistic use cases but were not supported. Servers were either not designed to be deployed on several geographically distributed locations or failed to work reliably when these setups were exercised. Some problems were partly solved during DC2, but experience generally showed that much of the middleware was put into production without proper testing cycles. Addition and updates of replica-catalogue entries was not a problem for DC2, mostly due to the fact that these operations were issued by single (or very few) jobs at a time. Problems while adding or updating entries were encountered when the replica-catalogue servers were unavailable, but this was mostly solved during DC2 and currently the servers very rarely fail. Querying was and still is a critical bottleneck. Efficient queries cannot be performed at all. Relying on application-specific metadata associated with each file proved to be very slow and its usage for querying was mostly dropped during DC2. Indexes on key elements (such as storage locations) are still missing. Collections/grouping of files is not supported, which means scoping of queries is not possible (full replica catalogue queries are in practice quite common).
Besides replica catalogues, the lack of a robust and unique information system also proved to be a problem. There is no automatically managed, reliable listing of ATLAS storage resources indicating the capabilities, reliability and QoS of each resource, as negotiated by ATLAS. The data transfer components provided by the Grid services didn't provide a minimal level of managed functionality for most of DC2. SRM is still not broadly deployed, so ATLAS itself has the task of debugging GridFTP server errors and trying to understand the cause of site problems. This infrastructure should be managed by the Grid middleware itself and meaningful errors should be reported back.
Prior to the start of DC2, DonQuijote was developed as a small tool to locate files and issue file movement requests between Grid flavours using Grid middleware. It was expanded in the light of experience to compensate for missing (or not working) functionality. DonQuijote eventually became a single point of failure since all production jobs depended on its functionality. The DonQuijote architecture was not originally designed to scale to handle production requests, but this was mostly solved during DC2. Nevertheless, DonQuijote was only partially successful in its goals. The file validation performed by DonQuijote at file registration proved insufficient, because in real operation entries that once were valid become corrupted later. This exposed the need for a continuous validation process to routinely check catalogues and sites for incorrect entries. Implementing this was not practical due to poor performance of the catalogues, and also due to the fact that DonQuijote (and the replica catalogues) do not understand the 'dataset' concept, so organizing validation in a scalable way above the file level was not possible. Also, the lack of validation features on GridFTP servers (or alternatively the lack of a managed, reliable file transfer component) was a further problem. Site disks failed and inconsistent replica-catalogue entries had to be manually fixed by ATLAS. Problems were also found in two areas important to end users: delivering reliable end-user client tools for accessing data, and reliable file movement. Both are still much too dependent on low-level Grid components which are not yet stable, GridFTP front-end servers to mass storage systems and slow queries on replica catalogues being the main bottlenecks.
At the operations level, there was a shortage of manpower especially in the areas of networks and data transfer (to interact with individual sites) and monitoring. There was insufficient communication and coordination between sites and ATLAS production managers in ensuring that sites were provided with needed input data by the time processing was scheduled to start, and that production outputs were promptly made available.
These experiences have provided important lessons and guidance for the design of the next-generation system described below.
Here follow the principal design precepts and requirements driving the design and implementation of DQ2.
The scenarios and use cases following from the ATLAS Computing Model that drive the DDM system design are described here.
Raw data flowing into the Tier-0, managed production of ESD and AOD, and simulation production will all yield datasets (file aggregations) of an operationally convenient granularity for cataloguing and distribution. Raw data files for a particular run may constitute one dataset, for example, with associated ESD and AOD another, and all of them aggregated for distribution to a Tier-1 centre. Production operations will rely on input datasets distributed in advance and available at time of processing at the production site.
Data aggregation may occur at multiple levels for multiple purposes. In the example above, a RAW+ESD+AOD aggregation of all produced data is appropriate for defining the data units to be replicated from Tier-0 to a Tier-1. Replication of analysis data to a Tier-2 would be on the basis of a different aggregation, e.g. all AODs from streams used in a Higgs analysis. Data aggregrated for replication or other purposes may later have to be split into subsets; for example, a replicated block of data may be subdivided at the destination for further distribution of subsets to processing farms. The system should simultaneously support such multiple, overlapping, layered aggregations (ie dataset aggregations, which may be hierarchical, with a given dataset able to appear in multiple aggregations/hierarchies).
Analysis groups and calibration teams will also conduct managed production-type operations, with workflows similar to (but more frequently iterated than) managed production. Data distribution patterns will also be similar.
Datasets created in DAQ, production, calibration, and analysis operations need to be replicated to interested recipients in an automated manner. Managed distribution operations need mechanisms to establish `subscribers' to particular data sets and have automated replication proceed accordingly. The system should support automated replication not only of static, predefined sets of data but dynamically changing sets (e.g. `replicate all new Tier-0 ESD datasets to institute X'). The system should allow for use of replicated data at the destination prior to completion of the replication (e.g. commence processing of an imported ESD dataset when the first constituent file arrives, not the last).
Automated mechanisms for reliably migrating files produced at a source to an archival destination, with the files catalogued for accessibility later, must be provided. For example, the migration of data files as they are produced online to Tier-0 mass store.
Data discovery at the dataset level and the file level must be fast and efficient ATLAS-wide: from anywhere in ATLAS it must be possible to discover datasets and files residing anywhere in ATLAS. Similarly ATLAS-wide replication must be supported down to the file level. From a regional Grid production system needing to locate and replicate an input dataset to an individual physicist needing a particular raw data file to diagnose a detector problem, it must be possible for anyone anywhere to locate efficiently and - subject to cost controls - replicate data residing anywhere.
To support physics analysis, essentially the full capability of the system (definition and cataloguing of datasets, data discovery, data replication and access) needs to be made available at the level of the individual user - of which there will be many hundreds at any one time - with appropriate controls on access, individual resource usage, and collective end-user resource usage relative to production usages.
Regional Grids will be engaged in both ATLAS-level operations (the `ATLAS share' of regional resources) and regional operations (autonomous activity driven by the interests of the region). The DDM system should smoothly integrate ATLAS-level regional operations into the overall ATLAS DDM. The DDM system should also be usable (at the discretion of the region) for autonomous regional operations.
The system architecture arrived at to address the requirements and usage scenarios described and support the ATLAS Computing Model is based on hierarchical organization and cataloguing of file-based data, and the use of these hierarchies (there is not one unique hierarchy) as the basis for data aggregation, distribution, discovery and access. Files are aggregated into datasets, datasets are aggregated by dataset containers, and dataset containers can be organized in a hierarchy to express flexibly layered levels of containment and aggregation. None of the assignments (file to dataset, dataset to container, container to hierarchy) need be unique; different aggregations will be appropriate in different contexts, and the architecture has the flexibility to express whatever aggregations or `views' of the data are required.
The data aggregations used as the units of data distribution around the collaboration provide a natural unit for looking up data locations, and the architecture is based on these (data blocks). Global data lookup at the dataset level rather than the file level affords better scalability in two respects: the entity count is down by orders of magnitude (we expect far fewer datasets in the system than files), and any dataset attribute may be used as the basis for partitioning catalogues into multiple instances (e.g. a dataset location or content lookup could first resolve that the dataset belongs to running period 2009a, and accordingly route the lookup to a catalogue instance for that running period). P2P technologies and searching algorithms may prove useful for steering queries to catalogues when we have multiple instances of them; this will be explored in the implementation.
Datasets and their containers that are used for distribution and data-location discovery are required to be immutable once their content is defined, such that the content of these data blocks is uniquely defined and stable. This allows the dissemination of this information around the collaboration for rapid, scalable lookup of data location without introducing a complex catalogue-consistency problem.
The principal components and features of the architecture are described in the following sections. Figure 4-1 shows the major catalogues in the system and the interactions with DQ2 services and user applications (production operations, end users). Initial implementation choices for the current prototype (discussed in Section 4.6.6 ) are also shown.
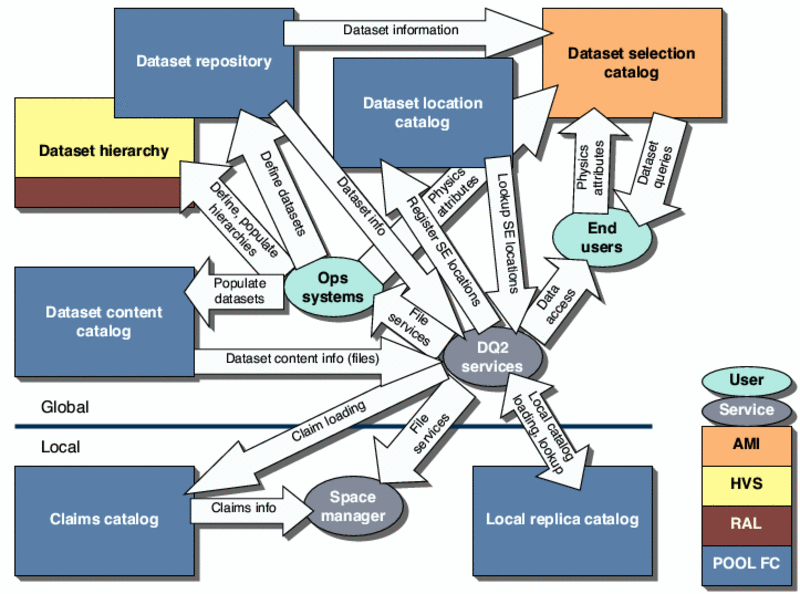
Figure 4-1 Architectural overview of the DQ2 distributed data management system
For the purposes of the DDM system a dataset refers to an aggregation of files plus associated metadata descriptive of the dataset itself and its constituent files. Datasets typically contain event data sharing some association (temporal, physics selection, processing stage, etc.), but can contain any sort of file-based data. A dataset is identified by a unique dataset ID (DUID). All files managed by the DDM system are constituents of datasets. A file can be a constituent of multiple datasets. Constituent files are identified by logical identifiers (LFN, GUID). Datasets hold a mutability state which can be unlocked, locked or frozen (permanently locked). Datasets that are not frozen can be versioned, to support discrete changes in their content tagged by version IDs. Different versions of a dataset share the same DUID; the composition of a DUID with version ID defines a version-unique identifier, VUID. The content of mutable datasets can be changed in any manner (additions or deletes).
Datasets can themselves be aggregated into container datasets consisting of other datasets (including other container datasets), plus metadata associated with the container dataset. Container datasets cannot directly contain files; only other datasets. Container datasets thus implement a hierarchy (tree) of datasets. Container datasets also hold a mutability state and (if not frozen) a version.
The dataset hierarchy implements hierarchical organization of datasets via container datasets. A dataset hierarchy is not intrinsic to the datasets involved; the hierarchy is an externally imposed organization of pre-existing datasets. A dataset can appear in any number of hierarchies. The dataset hierarchy supports this flexible organization of hierarchical dataset trees of arbitrary depth, with support for versioning at the nodes of the hierarchy such that the dataset content of a container dataset can be changed and versioned.
A dataset repository is a catalogue of datasets. Each dataset is represented by one entry in the catalogue, identified by a unique ID (DSID) and a name string (also unique). The repository catalogues the DDM system metadata for datasets, and has the ability to catalogue any content-specific attributes of the dataset that it is found to be useful to record here (it is unspecified at this point what, if any, metadata not strictly needed by the DDM system should be recorded in the dataset repository). All dataset versions are catalogued in the repository. The combination of DSID and version ID uniquely identifies a dataset version (DSID is the same across dataset versions).
The dataset repository serves as the principal catalogue and lookup source for datasets defined and made available by the DDM system. It catalogues container datasets as well as file datasets. The repository is not the means by which physicists perform queries to select datasets of physics interest. Rather, the dataset repository must support the efficient export of dataset information to physics-selection catalogues and tools such as the dataset selection catalogue. The dataset repository defines the dataset in terms of its data content; the dataset selection catalogue adds descriptive queryable information such as physics content, data quality, luminosity etc. (information which may change over time).
There will not be one monolithic dataset repository. The repository will be partitioned into multiple instances on the basis of function (different instances possibly having different attribute sets), scope (e.g. distinct repositories for local and global datasets), and for scalability purposes (e.g. by running period).
A dataset selection catalogue is the catalogue by which physics selections are made to identify datasets of interest. It is not a part of the DDM system, but receives information from the DDM system (the dataset repository) on file-based datasets and associated metadata. Other data sources add physics metadata to the dataset attributes recorded in the dataset selection catalogue to enable physics selections.
A dataset content catalogue records the logical file constituents of datasets. These catalogues record all (logical) files managed by the DDM, with global scope, so scalability is a major issue. Organization of the files in terms of datasets is the means to achieving scalability. There will not be one monolithic dataset content catalogue. An ensemble of content catalogues partitioned according to dataset metadata will share the cataloguing load. Dataset content lookup will proceed by 1) dataset lookup in the repository, retrieving metadata; 2) identification of the content catalogue, either rule-based using dataset metadata or via explicit recording of the content catalogue in the repository; 3) content lookup in the content catalogue. Dataset-dependent determination of the appropriate content catalogue requires this one pass through the repository, but the benefit afforded is flexible scalability in content lookup through content-catalogue partitioning.
Dataset content is made available in global scope in order to support file-level lookup with reasonable efficiency. File lookup will generally proceed from a context in which the file is known to reside in one of a known ensemble of datasets (from the processing history), enabling quick determination of the containing dataset via the content catalogues and thereby quick resolution of site-level file location via dataset location lookup mechanisms.
Physical file locations at a site are available only at the site (SE) level (the level at which this information is managed and relevant), via the local replica catalogue.
A data block is a frozen (permanently immutable) aggregation of files for the purposes of distributing data and thereafter finding it again. A data block is an instance of a dataset or container dataset. That is, it can be directly a collection of files, or a hierarchical collection of datasets. Constituent datasets within a data block are themselves data blocks (i.e. must be frozen).
Data blocks are the unit of data replication and data location lookup used by the DDM system. A data block must be wholly resident at a given location (site or SE), modulo temporary incompleteness during block creation or transfer, in order for it to be registered in the system as present at that location.
When a data block is replicated to a given location, the block's presence at that location is catalogued (via the data location service below). This catalogue provides the mechanism for discovering data location. This usage is why data blocks are required to be frozen: if their content were allowed to change, ensuring the correctness and consistency of data block location catalogues to support data lookup would be much more difficult.
Data block constituents of a container block can themselves be registered in the location catalogue, thus supporting different granularities of data distribution appropriate in different contexts (e.g. dissemination of RAW+ESD+AOD from T0 to T1 vs. a T2 picking up AODs only from a T1).
The data location service provides lookup of the site locations at which copies of data blocks can be found. It uses a dataset location catalogue to record data block locations. When a site obtains a replica of a data block, it registers the presence of the block at the site via the data location service. A container block can be registered only if all constituent blocks are available (and any constituent blocks which might be used on their own should also be registered).
The data subscription service enables users and sites to obtain data updates in an automated way via `subscriptions' to mutable datasets, subscription datasets. Subscription datasets may contain either files or other datasets (container datasets). Subscription datasets are versioned, so their content can change discretely by version over time. When a dataset is updated, it is unlocked, its content is updated (with insertions and/or deletions), the version tag is updated, and it is locked again. The data subscription service can then propagate the new version to subscribers. A `continuous update' mode will also be supported in which dissemination of updates is triggered not by appearance of a new version but by any change in the subscription dataset's content (first and second use cases below). The subscription system is implemented at the ATLAS application level as a means of automating and managing data movement, and makes no special demands on the underlying middleware and facilities services used to move data.
Subscriptions are inserted in the dataset location catalogue.
Subscriptions can serve a number of purposes, e.g.
The globally scoped components of the DDM system record file information only at the logical level (GUID and LFN). The physical location of a file on a storage element is information specific to an SE, and so is recorded (only) at SE scope, in a local replica catalogue at the SE. The `local' scope of a replica catalogue is subject to ATLAS policy, which may be Grid-dependent; the scope may be one SE (most typical), or a set of SEs/sites within a Grid (e.g. to support a set of small sites via one catalogue), or even an entire Grid (the approach used in the present system, but not scalable and therefore not likely to be carried over to the new system). In addition to scalability, delegation of physical replica cataloguing to sites affords them the ability to flexibly and autonomously manage data location on their SEs. The limited scope and therefore scale of the local replica catalogue makes the logical-to-physical deference a minor overhead in navigating to physical files.
Another component of local rather than global scope is the space management service. Users and production jobs can pin data on disk by registering a `claim' on a disk-resident dataset or file with specified lifetime. Claims are recorded in a claims catalogue. Multiple claims on a given resource will result in multiple claims in the catalogue; the resource will be eligible for deletion when all claims are expired. The space management service uses claims-catalogue data and DDM tools to clean up (delete) data for which claims are expired (or, if necessary, to apply a prioritization algorithm to delete live claims to sustain a high watermark level of disk space). The space management service can also check consistency and integrity of the catalogue by comparing catalogue and SE contents (a spider-like function). The space management service can operate either as a persistent daemon or as a periodically submitted batch job.
Sites will need a local catalogue of locally resident data blocks and their local state (completeness, disk-resident, etc.). The claims catalogue can fulfil this need.
All managed data movement in the system is automated using the subscription system described. Replication tools can also be used directly for automated, reliable transfer of individual datasets or files, e.g. by end users, but subject to usage and resource controls. Data movement operations should aspire to most data movement being done in a managed way by production, physics working group or regional operators, with end-user data movement a minor contributor. The system must nonetheless offer convenient and robust end-user data movement, including support for `off-Grid' endpoints such as laptops.
Managed data movement proceeds through block transfers triggered by subscription fulfilment. Data movement is triggered from the destination side, such that local uploading can be done using site-specific mechanisms if desired, with no requirement that other sites be aware of these specialized mechanisms. A number of independent entities per site are involved in the block movement process to perform the principal steps of the movement process: fetching of the set of logical files to be transferred on the basis of the block content minus any files already present locally; replica resolution to find the available file replicas via the dataset location catalogue, content catalogue and local replica catalogues; allocation of the transfers across available sources according to policy; bulk reliable file transfer; and file- and block-level verification of the transfer.
Multi-hop transfers will sometimes be required. These will be supported via chained subscriptions through the intervening hop sites. For example if for efficiency or bandwidth reasons transfers between CERN and site X should proceed via Tier-1 centre Y, then Y will hold a subscription to the CERN resident data and X will subscribe specifically to Y's instance such that X receives files via Y.
The block transfer service utilizes two site-local catalogues for managing transfers. A local content catalogue recording the files still needing to be transferred to complete the block, and a queued transfers catalogue acting as a state machine for active file transfers (see the implementation discussion below).
With the exceptions of the local replica catalogue and space management service, the catalogue components described are global in scope. We foresee replicating copies of global system catalogues (or subsets of them) down the tier hierarchy as read-only replicas in order to offload central services for usages able to tolerate slightly `stale' data. We are working with the 3D project to put in place the infrastructure to manage the replication, updating and use of remote replicas. Writes will be done only to the central master instances.
A further means of managing load and increasing scalability is partitioning of global system components through the use of multiple instances with distinct scopes. This will certainly be done for the dataset content catalogue, as discussed above. It may be done for other components as well, motivated not just by scalability but also by managing access rights, as discussed in the next section.
We foresee also that distinct local instances of at least some components will be required, e.g. a local instance of dataset catalogue infrastructure to define and manage private or temporary datasets that define data aggregations used by local production operations and/or local analysis users, and a local subscription infrastructure to support data distribution for production and regional dissemination of data (e.g. Tier-1 to Tier-2s). The catalogue infrastructure foresees `publishing' metadata to distinguish strictly local content from content that can be marked ready for publication upwards to the global ATLAS system.
As a more extreme case, we also foresee the possibility of complete clones of the full DDM system. A Tier-1 centre, for example, may want to install and operate an instance of the full DDM system, not coupled to the ATLAS-wide system, with the scope of the clone system being the service region of the Tier-1. This instance could be used for data management of resources `private' to the region independently of the management of ATLAS-wide resources.
Use of the system normally requires Grid authentication in order to establish virtual-organisation identity and role(s). All data in the system is readable by all ATLAS VO members, but not by others. Physical files on storage systems are owned by the DDM system (a DDM userid), with Unix read permission granted to a Unix group encompassing ATLAS users. All writes and deletes to managed data areas are managed by DDM system processes.
Roles needed are reader, writer and administrator. These are the roles which will be supported for database accesses within the authentication infrastructure being developed by the 3D project, so assignment of these roles to relational catalogues in the system will be supported. A user identity, determined typically from a Grid certificate, is mapped to the appropriate DB roles based on VOMS (or equivalent) information and a policy module managing role mapping for a particular database.
By default, all authenticated ATLAS users hold the reader role for all data. The writer and administrator roles are assigned to users for specific contexts/subsets of the system for which they are entitled to such access. Where the system catalogues are partitioned along functional lines, this contextual role assignment can happen at the catalogue level. For example, a physics-working-group (PWG) dataset repository (distinct catalogue instance) could have administrator rights assigned to the PWG leader and writer rights assigned to PWG members, while the repository for main production would grant these roles to the production system operators.
It will not be practical in all cases to partition the system such that user IDs map to roles at the whole-catalogue level. An example is user-level catalogues: the system must support user-level capability to define and work with datasets, but a catalogue infrastructure per user would be impractical. In this case, an authenticated user must be allocated write/administrator rights only to a subset of the catalogues `owned' by the user. This can be implemented in a file catalogue supporting a Unix-like hierarchy and ACLs on `directories' which can correspond to a user directory. The LHC File catalogue (LFC) supports this functionality, and will be tried out as a means of supporting this case
The implementation approaches being pursued for the components of the first DQ2 version are described here. Implementations may evolve in subsequent versions depending upon the success of the initial implementation and the availability of new third-party software.
A common element in many of the component implementations is the use of the POOL File Catalogue (POOL FC), both its interface and its implementation. The functionality of many of the catalogues in the system is a close match to that provided by a file catalogue (basically, one-to-many string lookup plus associated metadata). In view of this, we use the POOL FC interface for these components in order to leverage a robust existing component for which many relevant back-end implementations are available. Furthermore, we use POOL's own FC implementation in many of the present prototype components, since it offers ease of use, robustness, high performance, and a useful range of back end technologies (Oracle and MySQL via RAL, XML).
The repository is implemented using the POOL FC. Given a dataset ID or name, it returns information on the dataset and provides navigational information to dataset constituents (logical files, other datasets). The FC FileID corresponds to dataset ID (DSID), and LFN corresponds to dataset name. Additional metadata attributes include version, mutability state, creation date, expiration status, publication status (local, global, private, ready for publication), and provenance reference. A supplementary table records dataset versions (DSID, version ID, version-specific metadata)
The dataset hierarchy augments the dataset repository with information on the hierarchical structure of container datasets, and supports versioning of container datasets. A possible implementation approach, still to be tested, is to use the Hierarchical Versioning System (HVS) developed by ATLAS and LCG AA.
The dataset content catalogue is implemented using the POOL FC. Several instances are used, partitioned on the basis of dataset metadata to achieve scalability. The FC FileID corresponds to dataset ID (DSID), LFN corresponds to constituent LFN, and PFN corresponds to constituent GUID. Additional metadata attributes include dataset version number and file-content metadata (e.g. event count)
The dataset location catalogue is implemented using the POOL FC. For a given dataset, it returns a list of site identifiers holding a copy. For immutable datasets (data blocks) it acts as a catalogue of block locations. The location catalogue is also used to implement subscriptions: a site registered as a holder of a DUID (dataset-unique ID) for a mutable dataset holds a subscription to the dataset, and new versions (identified by version-unique IDs, VUIDs) are delivered to the site. A site holding only a specific version of a mutable dataset is registered as a holder of the VUID rather than DUID. The FC FileID attribute corresponds to dataset ID (DUID or VUID), LFN corresponds to dataset name, and PFN corresponds to site identifier. Additional metadata attributes include version/completion status, date, owner, and availability (resident at site, or accessible from site).
The claims catalogue is implemented using the POOL FC. Separate instances record dataset claims and file claims. The FC FileID attribute corresponds to claim ID, LFN corresponds to owner, and PFN corresponds to dataset or file resource that is claimed. One claim can reserve multiple resources. Additional metadata attributes include claim category or role level (user, group, system), creation time, originating processor/job, lifetime, and status (pending, granted, terminated, expired).
The local replica catalogue is implemented using the POOL FC. The back-end implementation that is used may be Grid or site dependent, but must support the POOL FC interface and meet performance requirements. The catalogue provides logical-to-physical file lookup for files at the local site (or in the region of the catalogue's scope). It provides both GUID and LFN mappings to physical files.
ATLAS has requested via the LCG that sites offering mass storage make their services available via uniformly robust and functional SRM interfaces offering the functionality of SRM 1.1 plus (if possible) the space reservation features of SRM 2. Other functionality of SRM 2 and SRM 3 is not required.
Present tools for data movement are GridFTP and SRM, used directly by an in-house reliable file transfer (RFT) system in DQ. DQ2 will take the same approach if robust RFT systems are not available from middleware providers, but we are first seeking a middleware RFT system that will meet our needs. The LCG/EGEE (gLite) FTS is currently under evaluation.
Data movement is driven from the destination side. Transfers typically have a gsiftp: or srm: source and a destination that is either one of these or something site-specific. All sites must provide external access via gsiftp and/or srm. Within the site, site-specific transfer or upload mechanisms can be used.
A transfer task first scans the local file catalogue to determine whether any requested files are already present (e.g. due to file overlap with a block already present). If any are found, claims are asserted on those files to protect them from deletion. Also, claims are asserted on source data block(s) prior to commencing the transfer, to protect from deletion during the transfer.
A state machine is used to persistently record transfer status for all files being moved by all active replication tasks at the site. If two tasks are replicating the same files (fulfilling subscriptions on datasets with overlapping content), the state machine will ensure that overlapping files are transferred only once.
Data sources are discovered by using the data location features of the architecture: the data location catalogue resolves the available site locations for a dataset, the dataset content catalogue provides LFN content, and the replica catalogues of the site or sites selected (on the basis of cost/efficiency) as data sources are used to resolve LFNs into physical files (storage URLs). A replication task will not necessarily use only a single source: if a data block to be replicated has instances at several accessible sites, the replication task can specify a prioritized list of sites to try as sources, and the prioritization can differ file to file in order to spread the replication task across (functional) sites.
DQ2 system development takes place within the DDM subproject of the ATLAS database and data management project. This activity encompasses
System development responsibilities are shared between the core ATLAS data-management team and regional Grid participants (who may also be core team members). The core data-management team has primary (but not exclusive) responsibility for
Regional Grid participants have (over and above any core team responsibilities if they are core team members) responsibility for
Deployment and support for the relational database services upon which many DDM components rely is provided by the database services activity discussed below, with the assistance and support of the DDM system development team. Operation of the DDM system is the responsibility of the ATLAS Computing Operations organization. DDM system developers provide direct support to operations and end users on usage of the system, debugging, feedback gathering and improvements, etc.
The development and deployment timeline for DQ2 is as follows:
| | |
Copyright © CERN 2005