  |  |
Computing Technical Design Report
| | |
Computing Technical Design Report
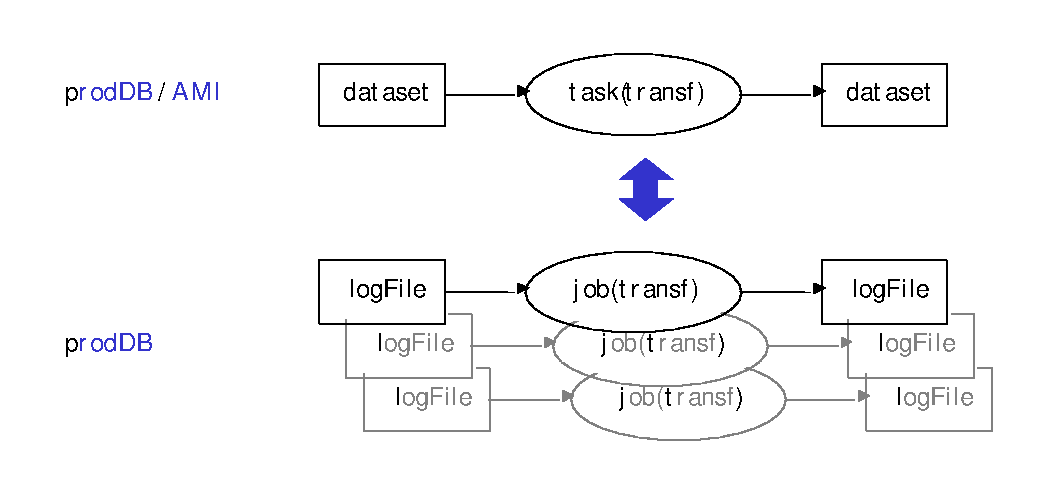
The production system distinguishes between two levels of abstraction (see Figure 5-1). On the higher level, input datasets are transformed into output datasets by applying a task transformation. The process of doing this is called a task.
Datasets are usually quite large and consist of many logical files. At a lower level of abstraction, input logical files are transformed into output logical files by applying a job transformation, as shown in Figure 5-1. This process is called a job.
The architecture of the production system was designed in mid-2003 with the following goals in mind:
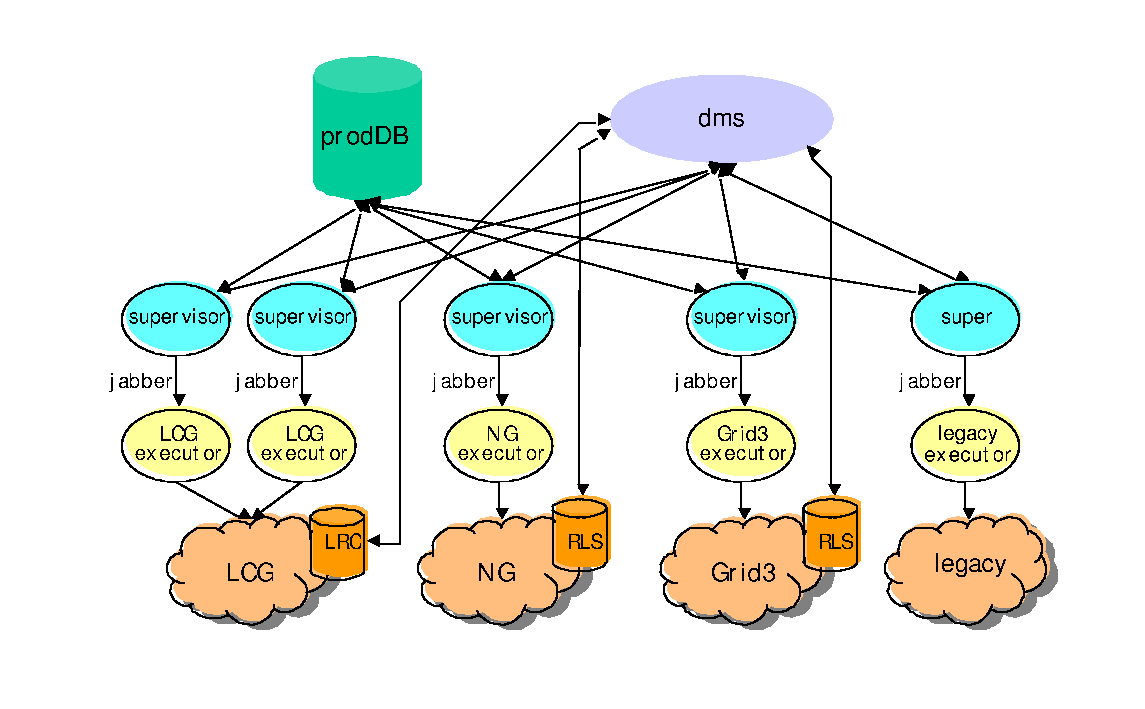
The resulting design is shown in Figure 5-2. It is based on four components: a central production database (ProdDB), a data management system (dms), a supervisor component, and an executor component. In the following subsections we will address each of these components separately.
By adopting a component-oriented design and additionally allowing the components to run as agents on different servers, communicating asynchronously with each other, a lot of flexibility, both with respect to the logical composition of the system and to its physical realization, was made possible.
Note that the design assumed that each Grid system knows how to manage its workload and collect information about its own system. This had the advantage that we did not have to invest effort in producing our own equivalents of this functionality. However, it also made the overall production system reliant on the performance of the individual Grid systems, which was found not to be adequate in some cases. Of course Grid systems are not yet perfect, but the production system has only limited possibilities to compensate for such imperfections.
The job transformation is the script that sets up the run-time environment, allows possible compilation of patches to software in a release, runs the Athena executable, parses the log file for known warning and error messages, and tidies everything up at the end. Currently it is implemented as a shell script. It can include any data file that may be missing from the release or that may be needed for a particular job.
There are two kinds of transformations: production (system independent) and KitValidation (KVT, test oriented). They differ in the call method, with positional arguments for production and switched parameters (name-value pairs) for KVT. Building the transformation for production jobs is at present a manual operation; the transformation is then put into a Pacman cache and loaded by Grid jobs at start-up.
Work is in progress to provide a generic transformation for all usages, including non-production jobs. The intention is to move to Python (instead of shell) scripts, as in this way the transformation can be seen as an extension of the jobOptions. The transformation will also check the integrity of the expected output file at the end of the job. (This needs the knowledge of the number of output events as counted inside the Athena job.)
There is only a single logical production database. The physical realization of the database may be distributed and/or replicated, but to the other components in the design it will present itself as a single entity.
The database holds tables with records for:
A job-transformation record describes a particular combination of executable and release. The description includes the signature of the transformation, listing each formal parameter together with its type (restricting the possible values) and its meta-type (indicating how the values should be passed to the executable).
Each job-definition record points to its associated job transformation. Other fields allow one to keep track of the current attempt at executing this job (lastAttempt), which supervisor component is handling this job (supervisor), what is the relative priority of this job (priority), etc. The bulk of the job definition is, however, stored as an XML tree in the field jobXML. It lists the actual values to be assigned to the formal parameters of the transformation and additional information about logical input files and logical output files.
For each job definition there can be zero, one, or more job-execution records, corresponding to each attempt at executing the job. Each attempt has a unique number which is appended to the names (both logical and physical) of all files produced, ensuring interference-free operation even in the case of lost and/or zombie jobs. The execution record also records information like start- and end-time of the job, resources consumed, where the outputs were stored, etc.
In the last table, logicalFile, the production system stores all metadata about logical files. Most of the information is redundant with respect to the information stored in the respective metadata catalogues of the Grids (size, guid, md5sum, logicalCollection), but at the time the production system was developed these metadata catalogues did not support schema evolution and ATLAS did not know a priori what metadata was needed. Consequently, it was decided to deploy temporarily our own catalogue in addition to filling and using the existing ones.
The production database used in 2004-2005 for Data Challenge 2 and subsequent productions was implemented as an Oracle database hosted at CERN. A MySQL version of the production database is also available for small-scale productions.
The next component, called the supervisor, takes free jobs from the production database and hands them on to one of the executors with which it is connected. The information about jobs is exchanged using XML, usually wrapped in XMPP (using the Jabber protocol) or wrapped in SOAP using web services. As its name suggests, the supervisor will follow up on the job, asking at regular intervals about the job status until the job is declared `done' by the executor. At that point, the supervisor will, for successful jobs, verify the existence of all expected outputs, and, if all is as expected, will rename them to their final logical name (by dropping the attempt number from their temporary logical name). Additionally, the files will be added to the logicalFile table together with any metadata produced by the job and returned by the executor. In the case of a failed job the supervisor will simply release the job in the production database, so that it can be picked up again if the maximum number of attempts is not yet reached.
The supervisor does not perform any brokering. The handing-out of jobs is based on a simple "how-many-do-you-want" protocol. The supervisor asks the executor how many jobs it wants (possibly qualified with resource requirements) and the executor replies with a number (possibly qualified with, not necessarily the same, characteristics). The supervisor may then send a number of jobs to the executor, which in turn may choose to process or refuse them. The non-binding nature of the protocol allows both very sophisticated and very simple implementations to co-exist on both the executor and supervisor side.
For efficiency reasons an implementation of the supervisor can keep state but the design does not require this. Having a stateless component obviously makes it more resilient against crashes.
The supervisor implementation used in 2004-2005 is Windmill [5-5]. Each Windmill instance connects with a specific executor, and manages all jobs processed by this executor. Since Windmill is stateless, it can be robustly reconnected to the same executor without loss of job-status information.
The task of the executors is to interface the supervisor to the different Grid or legacy systems. They translate the system-neutral job definition into the system-specific language (xrsl, jdl, wrapper scripts, etc.), possibly adding some pre- and post-processing steps like staging in/out of files. The executors implement a system-neutral interface with the usual methods: submit, getStatus, kill, etc. Again, the design does not require the executor to keep state.
Five executors were developed and deployed in 2004-2005 and used for Data Challenge 2 and subsequent productions:
The Advanced Resource Connector (ARC) is a Grid middleware suite developed by the NorduGrid collaboration. NorduGrid's ARC has been deployed at a number of computing resources around the world. These resources are running various Linux distributions and use several different local resource-management systems (LRMS). Despite using different LRMS and specific information providers, the different sites can present the information about their available resources in a uniform way in ARC's information system. This information system is based on the Globus Monitoring and Discovery Service (MDS). The information provided is used by the brokering algorithm in the ARC user interface to find suitable resources for the tasks to be performed, as well as by various monitoring tools like the NorduGrid Grid Monitor. NorduGrid's ARC is fully integrated with the Globus Replica Location Service (RLS) [5-10]. This allows jobs sent to an ARC-enabled site to specify input-file locations as an RLS catalogue entry instead of a physical-file location. A job can also, if desired, automatically register created output files in an RLS catalogue.
The ATLAS production system executor for NorduGrid's ARC, Dulcinea, is implemented as a C++ shared library. This shared library is imported into the production system's Python framework. The executor calls the ARC user-interface API and the Globus RLS API to perform its tasks. The job description received from the Windmill supervisor in the form of an XML message is translated by the Dulcinea executor into an extended resource specification language (XRSL) job description. This job description is then sent to one of the ARC-enabled sites, selecting a suitable site using the resource-brokering capabilities of the ARC user-interface API. In the brokering, among other things, the availability of free CPUs and the amount of data needed to be staged-in on each site to perform a specific task is taken into account.
The look-up of input-data files in the RLS catalogue and the stage-in of these files to the site is done automatically by the ARC Grid Manager. The same is true for stage-out of output data to a storage element and the registration of these files in the RLS catalogue. The Dulcinea executor only has to add the additional RLS attributes needed for the DonQuijote data management system to the existing file registrations.
The Dulcinea executor also takes advantage of the capabilities of the ARC middleware in other respects. The executor does not have to keep any local information about the jobs it is handling, but can rely on the job information provided by the Grid information system.
Because of the diversity of the ARC-enabled resources in terms of which Linux distribution is installed on the various sites, the ATLAS software release is recompiled for various distributions. The ATLAS software release is then installed on the sites that want to participate in ATLAS productions. After testing the installation at each site, the ATLAS run-time environment is published in the site's Grid information system. By letting the Dulcinea executor request the run-time environment in its job description, only sites with the proper software installation are considered in the brokering.
The ARC middleware and the Dulcinea executor provided a stable service for ATLAS DC2 in 2004. Twenty-two sites in seven countries operated as a single resource and contributed approximately 30% of the total ATLAS DC2 production. Most of the resources were not 100% dedicated to the DC2 production. The number of middleware-related problems was negligible, except for the initial instability of the RLS server. Most job failures were due to site-specific problems.
The Grid3 executor system, Capone, communicates with the supervisor and handles all the interactions with Grid3 resources and services. Job requests from the supervisor are taken by Capone, which interfaces to a number of middleware clients on the Virtual Data Toolkit (VDT). These are used with information in Grid servers to submit jobs to the Grid.
ATLAS job parameters are delivered to Capone in an XML-formatted message from the supervisor. These messages include job-specific information such as specific parameters expected by the transformation (the executable), identification of input and output files, and resource-specific requirements for the job. Capone receives these messages as either Jabber or Web service requests and translates them into its own internal format before beginning to process the job. The transformation to be executed is determined from the input data contained in the supervisor message. The Globus RLS (Replica Location Sever [5-10]) is consulted to verify the existence of any required input files and serves metadata information associated with these files.
The next step is to generate a directed-acyclic graph (DAG) which is used to define the work-flow of the job. The job can now be scheduled using a concrete DAG generated from the previous abstract DAG with the addition of defined compute and storage elements. The Computing Element and Storage Element are chosen among those in a predefined pool of Grid3 resources. To select the resource, it is possible to use different static algorithms like round-robin, weighted round-robin or random, and some dynamic ones that account for site loads.
The submission and subsequent monitoring of the jobs on the Grid is performed using Condor-G [5-11]. On the CE, if necessary, all input files are first staged-in before the execution proceeds. The ATLAS software itself, an Athena executable, is invoked from a sandbox using a VDT-supplied executable. A wrapper script, specific to the transformation to be executed, is called first to ensure that the environment is set up correctly before starting any ATLAS-specific executables. The wrapper script also checks for errors during execution and reports results back to the submitter. In addition, the wrapper script performs additional functions such as evaluating an MD5 checksum on all output files. The Condor status of each job is checked periodically by Capone and, when the remote job completes, Capone resumes the control of the job.
Capone checks the results of the remote execution: the program's exit codes and the presence of all the expected output files. This is a delicate step since a large variety of errors may be discovered here, ranging from IO problems encountered during the stage-in process, to errors in the execution of Athena, to site characteristics that prevent Condor from exiting correctly. The next step towards job completion is the stageout of the output files that are transferred from the data area in the CE to the output SE. The transfer also involves evaluation of the MD5 checksum and file size of the destination file(s), to check the integrity of the transfers. Furthermore, some important metadata, like the GUID (a globally unique file identifier), is recovered from service files in the remote-execution directory. Finally there is the registration of the output files to RLS inserting logical filenames, physical filenames and metadata attributes required by DonQuijote [5-4], the ATLAS data-movement utility that allows data transfers between Grids.
Over the course of three months, July-September 2004, about one third of ATLAS DC2 production was executed on Grid3, keeping pace with peer projects using NorduGrid and the LCG. Efficiencies steadily improved as lessons learned at production scales were incorporated into the system. We found that two areas of Grid infrastructure are critical to distributed frameworks: job-state management, control and persistency, and troubleshooting failures in end-to-end integrated applications. The next steps in the project will make progress in those areas. The evolution of Capone is towards increasing its reliability, for example, implementing robustness to Grid failures, and making it more flexible to support user-based production for distributed-analysis jobs.
Lexor is the executor that submits jobs to the LCG-2 Grid. Lexor has been fully coded in Python, as this language encourages a modular, object-oriented approach to application development. First, a module implementing a generic LCG job class was developed. The code is based on the SWIG API to the workload-management system, developed by the Work Package 1 (WP1) of the European DataGrid (EDG) project for their User Interface. Through this API, this class offers methods for defining, submitting, and managing the job on the Grid. For job definition, a set of methods allows the manipulation of the underlying JDL description, either by direct access to the classAd attributes or via higher-level functions. Other methods are used to tune and perform the job submission, to monitor the job status (and extract single pieces of information from the status), and finally to retrieve the output sandbox of the job. A job-cancellation method is also provided, but is not yet used in the production system.
When it is in submission mode, the supervisor periodically asks for the number of jobs the executor is willing to manage. To answer this question, we issue a query to the LCG Information System to retrieve the number of free CPUs in the sites matching the requirements expressed in the supervisor request. Computing this number turned out to be a tricky task, because of the aggregated nature of the information published by the LCG Information System. Often we overestimated the real amount of available CPUs, because some of the advertized ones are not accessible by ATLAS jobs. This problem was temporarily addressed by defining one queue for each VO, but a refining of the information schema has to be considered.
Once submitted, a job is dispatched to the Computing Element (CE) selected by the broker and queued until the local batch system starts executing it on a Worker Node (WN). Before the required transformation can be started, several actions have to be performed on the WN, so the job has to be wrapped by an appropriate script. Typical actions are the interactions with external services, such as the repository where the transformation packages are hosted, or the DonQuijote server. The wrapper also embedded mechanisms to cope with temporary problems in the underlying Grid. A frequent problem is the occasional unavailability of ATLAS software, due to NFS problems between the CE exporting the software directory and the WN. Jobs being executed on such hosts fail at the very beginning, thus freeing a WN that attracts more and more jobs. To avoid this "black-hole" effect, the wrapper was modified to have the job send an e-mail message to the submitter about the problem, and then sleep for some hours. When it wakes up, the process is repeated until the software is found or the job is killed. This keeps the WN busy, preventing further attempts to run jobs on it.
The stage-in and the stage-out phases of the wrapper were also enclosed in a sleep-and-retry cycle. The LCG commands used to stage files are in fact very sensitive to failures or long delays in the services they rely on. The heavy work-load, imposed on these services by the high number of concurrent requests from the running jobs, sometimes caused them to become unresponsive for a while or even to crash. This affected all the running jobs, which, after having successfully executed the transformation, failed to stage the produced files to the output Storage Element. The retry mechanism doesn't completely solve the problem, but it allows the recovery of many jobs where the LCG commands hung. In fact, by killing by hand the command process, a subsequent attempt is triggered, which usually succeeds.
During the DC2 production in 2004, Lexor managed more than 100 000 jobs, including generation, simulation, digitization and pile-up. More than 30 LCG sites were involved, providing overall about 3 000 CPUs. The job management was shared, on average, among six Lexor instances owned by different users, each instance taking care of a maximum of about 800 jobs at a time. This threshold was decided in order to limit the size of the queries issued by supervisors to the central production database and to circumvent limitations of the resource broker.
Lexor-CondorG (Lexor-CG) was developed from the original Lexor executor to address the problem of slow job-submission rates to LCG resources. It was observed that the interaction with the LCG WMS at that time took up to 45 seconds per job, and this was too slow to keep the available CPUs filled. A simple calculation, assuming 4000 available CPUs and jobs lasting 8 hours, illustrates that a submission rate of at least 1 job per 7 seconds is required. Indeed, during the Rome production (early 2005) there were eight instances of Lexor required in order to approach this submission rate. The resource requirement, in terms of hardware, services (RBs), and particularly manpower, was deemed not to scale, and a different submission solution was sought.
CondorG is standard Grid middleware for remote job submission to CEs, and indeed it forms part of the LCG RB. In this case the RB chooses the destination CE, and CondorG submits to the named site. However, when given information about the resources, CondorG can also do the resource brokerage. This information is taken from the BDII and converted into the Condor ClassAd format.
The fundamental difference, compared with the original Lexor executor, is that the resource brokerage and the submission are done by separate components. The Negotiator and one or more Schedulers run on different machines, and scalability is achieved by increasing the number of Schedulers only. Furthermore, the scheduler is sufficiently lightweight to run much closer to the UI, perhaps on the same machine.
The interaction with the local Scheduler is therefore much faster, and job submission takes 0.5 s (cf. 45 s). Similarly the status and getOutput requests are instantaneous as the response is like that of a local batch system.
There are, however, two perceived deficiencies with this approach. First, if the UI machine hosts the Scheduler then it cannot be turned off, which is inconvenient if the UI machine is, for example, a laptop. For the Rome production this issue did not arise because the Windmill services must keep running on the UI. In general the UI could be a high-availability machine to which a user can connect with "ssh" to submit jobs. In terms of fault-tolerance, the CondorG scheduler will regain its state after a reboot. Lastly, CondorG does provide for separating the UI and Scheduler functionality - it is the Condor-C implementation that is included in the recent EGEE/gLite release. This option has not yet been tested.
A second concern was the lack of central logging and book-keeping (L&B) when using CondorG. We should stress "central" because there is in fact a local record of the stages in the job's life, and a mechanism exists to extract this to a MySQL database. The LCG central L&B has been identified as a potential cause of the poor performance, so not having this architecture is an advantage of CondorG. This does not prevent the L&B information being migrated to a central place, asynchronous to job submission.
Lexor was used as the basis for the Lexor-CG executor because its modular design allowed the easy exchange of the LCG submission with the CondorG submission. Everything else, including the run scripts, stage-in, stage-out, validation, etc. remained the same and was re-used. During production operation, improvements to Lexor were also applied to Lexor-CG.
The method of choosing how many jobs to submit to LCG was different. The number of free CPUs published on the Grid was thought often to be inaccurate and therefore best ignored. Instead jobs were submitted as quickly as possible until the queues were loaded to a configurable depth and then submission was throttled. This was achieved by placing the following in the job requirements: "...&& WaitingJobs+CurMatches < 0.1*TotalCpus". So for a 100 CPU sites, only 10 jobs would be queued, after which the site would fail the requirements. Jobs that cannot find a matching site will remain in the queue UNMATCHED. When the number of UNMATCHED jobs reaches a configurable number, then the executor submission is throttled.
This exhibits two features of CondorG not available in the LCG RB. CurMatches is a per-CE attribute that is incremented by 1 for each match made to that CE. When the information is refreshed it is reset to zero. This enables the matchmaking to handle stale information sensibly and leads to a round-robin job distribution amongst sites with similar ranks. The LCG RB tends to submit blindly to the highest-ranking site, until the information updates. This led to a slug of jobs going to each site and very poor job distribution in terms of queuing jobs unnecessarily.
The input and output sandbox mechanism had to be provided by the CondorG executor. The GRAM protocol ensures that the executable reaches the worker node, and that the standard output and error gets back to the submission machine. So we built the executable to be a self-extracting tarball containing the input sandbox. Similarly the output logs are tarred into the stdout. This provides the same functionality as the LCG RB sandboxing, but minimizes the number of file transfers, which for the RB each require two hops with time-consuming authentication and authorization.
The Lexor-CG executor began submitting jobs part way into the Rome production of early 2005. The production rate on LCG was immediately doubled, because of the full use of LCG resources. This was maintained over the course of the Rome production and two Lexor-CG instances, for fault tolerance, were able to match the production rate of eight plain Lexor instances. This was directly attributable to the higher submission rate.
During the reconstruction phase it was noted that having more executors was an advantage. The shorter jobs, with four output files requiring renaming and validation, meant that Windmill was now the bottleneck. Removing the job-submission-rate bottleneck was an important step towards identifying this, and it will be addressed in the future production system.
The legacy executor Bequest is designed primarily to be simple and provide an adaptable system which may be ported to any batch flavour. In spite of this aim for simplicity, it is inevitable that different environments and different batch systems deployed at sites will require some re-configuration of the executor. The development aims to keep this reconfiguring to a minimum. The Legacy executor aims to fit seamlessly into the production system providing the standard interface to the supervisor and to be indistinguishable, to all intents and purposes, from a Grid-implemented executor.
Bequest was developed using Python, thus allowing for rapid development and testing. The supervisor project development was also undertaken using Python and provides a simple executor template which was utilized during the development. In addition, several supervisor tools for the interpretation, processing, and creation of XML messages were also used by Bequest. The executor allows some site-specific configuration values to be set, such as the batch queues to interface to, and the maximum number of executor jobs allowed into these queues.
In addition to ensuring that Bequest provided the functionality to interface with the supervisor and run jobs on a local batch system, it was considered a design goal to ensure that it also provide an adequate level of persistency and fault tolerance. The executor is made persistent by storing the global-to-local job mapping and allowing queries access to this store. Thus when the executor fails, a persistent store of job information remains intact, and upon re-launching the executor the correct information about the assigned jobs can be obtained. This persistency is very important in a distributed system to ensure that failures in the system don't cause the loss of jobs at remote sites.
Bequest was primarily developed with a PBS batch system at the FZK centre in Karlsruhe, Germany. At various points during the development process the executor was deployed at alternate sites and adapted to their systems. Sites used include RAL (PBS) and CERN (LSF). Once a working framework was available, a parallel development was undertaken using the CCIN2P3 (BQS) system. The deployment at different sites allowed the executor to remain focused on its goal of providing a generic system with minimum required alterations for different sites.
The PBS-based executor for the FZK site was tested extensively with both event-generation and simulation jobs. In the final testing phase the executor was run with a continuous float of 200 jobs, with 400 jobs, with a typical duration of around 24 hrs each, being processed during this test. Although this number is somewhat smaller than the numbers available when using Grid-based executors, it is nevertheless convincing for a single batch system, and it is envisaged that the executor would be capable of scaling to even larger batch-system capacities.
The persistency and resistance to executor/supervisor failure was tested by killing either the executor or supervisor once jobs had been submitted to the batch system. The majority of jobs could be successfully retrieved, although in some cases the jobs were lost. More investigation is required into the mechanism by which jobs were lost, and to ensure that this possible cause of failure is corrected.
Between the start of DC2 in July 2004 and the end of September 2004, the automatic production system submitted about 235k jobs belonging to 158k job definitions, producing about 250k logical files. These jobs were approximately evenly distributed over the three Grid flavours. The definitions belonged to 157 different tasks, exercising 22 different transformations. Overall, they consumed ~15 million SI2k months of CPU (~5000 CPU months on average present-day CPUs) and produced more than 30 TB of physics data.
By design, the production system was highly dependent on the services of the Grids it interfaced to. This was known to be a risky dependency from the beginning and indeed we suffered considerably because of it. The Globus RLS deployed by both NorduGrid and Grid3 turned out to be very unstable and became reasonably reliable only after a series of bug fixes. We had a similar experience with several of the LCG services, e.g. the resource broker and the information system. Because the LCG is by design the most complex system of the three Grids, requiring many services to work at the same time, it is not surprising that the LCG had the highest failure rate of the three Grids.
Transient site misconfigurations and network failures were amongst the most frequent causes of job failures. The correctness of published information, some of which had to be handled manually at least at the beginning of DC2, turned out to be a very important factor in job and data distribution and in the efficient use of the available computing resources.
It was not only the Grid software that needed many bug fixes. The data challenge started before the development, let alone the testing, of the ATLAS production system was finished. As a result, various bugs had to be corrected, and new features introduced, during the data challenge period.
The experience with the distributed production system accumulated during Data Challenge 2 in 2004 was analysed through a review in January 2005 [5-12]. The bulk of the recommendations of the review panel were addressed by setting up a "Grid Tools Task Force", active in February and March 2005, which in turn produced guidelines for the "2nd version" of the production system, an action list, and an implementation plan [5-13]. While both the review panel and the task force concluded that the high-level architecture of the production system is basically sound, many of the underlying implementations have to be made more robust in order to shield ATLAS from the possible shortcomings of Grid middleware and of running conditions.
Tests during February 2005 of a dedicated Oracle database server for the ProdDB were positive, therefore the production was moved to the new dedicated Oracle server in March. After the move, the database response times were measured in production conditions, for queries submitted by supervisors and monitoring activities. The immediate effect was in an improvement by 2-3 orders of magnitude for some of the common queries, but there are some queries (logically not very different from other ones) that take an almost infinite time to get executed. It also appears that the whole database is read every few minutes. As the database is now dedicated, we could activate logging of all queries from the database side with the aim of finding out which queries are performed routinely on the database, by whom, and how heavy they are; investigations are in progress with the help of IT Oracle experts.
If after all these investigations the response time is still found to be inadequate, then, depending on the reason found from the query logs, we can improve indexing of the database, create numeric fields for commonly accessed string (or XML) fields, or investigate modifying the schema to have separate tables for finished and active jobs, so as to reduce the number of accessed records and separate production from accounting activities.
In addition, we have to make sure that there are adequate fields in the database tables to store the quantities needed for monitoring and accounting.
The use of the production database (or an extension thereof) for "user productions" and analysis jobs has been discussed during last the few months. Separate instances of the production database, implemented in Oracle or in MySQL, have been used to submit moderate-sized productions to the Grid by physics groups, with acceptable performance. Currently these additional activities are possible only because they are limited in number and in scope, as there is no way to assign relative priorities to jobs that are submitted to the Grid through separate systems.
On the other hand, having a single production database for all ATLAS Grid jobs may not scale and may introduce a single point of failure in the system. The solution (currently under study) may be in a system where resource providers take an active part in the definition of job priorities, allowing jobs to be submitted by different systems but with a different level of access to local resources (see Section 5.3.1 ).
The Windmill supervisor, developed in 2003-2004 for DC2 productions, had to cope with many more error conditions than anticipated. Its functionality had to be extended with respect to the original design, and at the same time its complexity increased considerably. The work model also changed during the early phases of DC2: we went from having a single instance of the supervisor that communicates with several instances of the executor, to running supervisor-executor pairs on the same machine. This change made the remote communication protocol between the supervisor and the executor, based on the Jabber protocol and Jabber servers, unnecessary.
Eowyn [5-14] is a new implementation of the supervisor component. The most important difference with respect to Windmill is the introduction of an additional interface layer between the supervisor and the executor that exchanges information using Python objects and defines a synchronous communication protocol that allows executors to answer immediately if they can. Underneath this layer the communication can still be implemented using asynchronous XML message exchanges (e.g. using Jabber), but in addition executors can also be plugged directly into the supervisor. Existing executors can work with Eowyn using an adaptor implementing the expected time-out functionality, and translating between Python objects and XML. For executors implemented in Python and translating the XML back into objects, it would of course make sense to eliminate this overhead.
Eowyn also reduces the number of queries to the production database as it keeps the state of active jobs in memory, in addition to keeping it in the production database. In case of a restart of an Eowyn-executor pair, the in-memory database is restored from the production database with a minimal amount of queries.
The Grid Tools Task Force [5-13] recommended continuing testing Eowyn and completing its implementation, with the aim of having it in production in summer 2005. The proposed modifications of interfaces from Windmill to Eowyn are under discussion in order to agree them with the authors of all the executors. Tests of Eowyn are starting from systems that are less dependent on Grid middleware: first Bequest, then Lexor-CG, and finally all other executors.
Existing executors have also been discussed by the Grid Tools Task Force [5-13]. An internal code review took place in this context, where authors of one executor looked in detail at the implementation of another. This exchange of experience resulted in concrete suggestions to improve the quality and above all the robustness of the code. The level of commonality between the Python-based executors will also increase.
Capone, the Grid3/OSG executor, has to provide a substantially larger functionality than the other executors, as Grid3 does not provide a job brokering and distribution system. The Capone team are working with the VDT developers in the US to move part of the current Capone functionality to future Grid3/OSG middleware. The aim is to simplify Capone for ATLAS users by transferring as much as possible of the complexity to Grid middleware.
The "agent" model, pioneered by LHCb with their Dirac production system [5-15], has been very effective for their organized productions in 2004-2005. Within ATLAS we have started exploring the strengths of this model and the possibilities of implementing it. The model consists in distributing a large number of identical jobs ("agents") that just set up the running environment, contact a central database ("task queue") and get a job (or jobs) to be executed locally. In this model all brokering is effectively done on the experiment's side. A central task queue would make it easier to assign priorities to jobs but could constitute a serious single point of failure; more complex schemes with several task queues (perhaps one per group or activity as defined in VOMS) are possible in principle but have not been investigated yet.
Like any system that performs complex tasks, the Grid has to expose its status to the end user, to allow for real-time monitoring and long-term performance analysis based on accumulated data. In what follows, we shall distinguish between two observation methods:
Both kinds of information relate to the same objects and their attributes, such that information collected by monitoring tools can be naturally re-directed for further book-keeping. However, the overlap is not complete, as some information is volatile and has no value in a historical perspective (e.g., proxy expiration time). Moreover, it is physically impossible to store all possible data persistently; hence, for book-keeping purposes, only a selected subset of monitored parameters is chosen.
Accounting is then based on the information provided by the book-keeping system.
By "monitoring" we refer both to "job monitoring", i.e. checking the progress in the execution of single jobs, and "Grid monitoring", i.e. checking the status of the Grid, including the availability of resources and our job distribution.
Monitoring tools do not require a database to store data permanently. Typically, Grid-monitoring tools involve small, local databases per service, populated by sensors or information providers with a certain regularity. Every update of such a database overwrites previously stored information, such that no service keeps long-term records of its own activity and status. Examples of monitoring systems integrated with Grids are:
The systems above are not application-specific, and are deliberately designed to accommodate only generic information. Nevertheless, each monitoring system can be set up to monitor different set of objects and their attributes.
In general, there are several objects that can be monitored:
Each of these objects has a set of characteristic attributes that can be monitored. For example, a computing facility can be characterized by its architecture, number of processors, ownership, etc. A job can be characterized by its name, owner, resource consumption, location, submission host etc. Table 5-1 lists a typical set of such parameters as used/needed by ATLAS.
A functional monitoring system needs to collect information in real time from a number of sources, including our production database, the various Grid-information systems, and local batch systems. By now, each Grid flavour has well-developed monitoring tools and ways to browse the information, usually through web pages. Central effort on monitoring, covering not only job submission and distribution, but also file transfer activities, has so far suffered from insufficient manpower.
Job-monitoring tools that we developed for DC2 in 2004 have shown the limitations of the concept of the single Oracle-based production database; repeated monitoring queries could effectively slow down the response time much beyond expectations. One possible solution that is under discussion would consist in moving all records relative to completed jobs (or perhaps completed job blocks) either to different tables or to a different database instance, so that monitoring queries would have to deal only with a much smaller number of "active" records.
Since all the monitoring systems are very different, ATLAS has not yet succeeded in producing a common monitoring tool for all three Grid flavours. Different approaches can be considered to achieve the goal of collaboration-wide monitoring:
An important activity related to job monitoring is the identification of error conditions and of the subsequent actions to be taken, automatically or not. We have defined a set of "standard" (or rather, most frequent) error conditions and have asked the developers of all executors to make sure that the error codes that come back from each job step are passed back correctly and mapped to our standard definition. In this way we hope to be able to increase the level of automation in the production system and concentrate on those job failures that may be due to ATLAS code.
Grid monitoring should in principle be done much more efficiently by the GOCs (Grid Operation Centres) than by the LHC experiments. In practice, because of the late start of the GOC activity (especially on the LCG Grid), we had to invest ATLAS effort into checking the status of the Grid sites, and the correctness of the information available through the information system, on a continuous basis. The set of tools for the LCG Grid provided recently by the LCG-GD group is very useful as a starting point and we are working with them on the customization and optimization of these tools for ATLAS.
Specifics of book-keeping are:
Book-keeping procedures are inherently connected to monitoring. The difference is subtle from the client point of view, but essential from the server side: information collected about a process or an object must be preserved permanently, well after the object ceases to exist. A good example is the job-exit code: whenever a job finishes, it is removed from the execution site, hence it cannot be monitored any longer. In order to ensure that the job exit code can be retrieved after its end, the code has to be stored permanently, in a dedicated database. Clearly, local monitoring databases cannot offer such persistent storage service since it will negatively affect their performance. Moreover, storing book-keeping information in a widely distributed database requires non-trivial solutions to prevent data loss and to provide fast, reliable and properly authorized access.
A typical book-keeping task, often confused with monitoring, is that of obtaining a production-status report: the number of jobs submitted, finished, succeeded, failed, their categorization by failure reason, the integrated resource consumption, the contribution per site etc. Monitoring systems cannot address such tasks, as they do not store all these data persistently. The procedure of producing such a report is similar to monitoring: the view must be refreshed at a certain rate. However, each consecutive report must include data used in previous reports, which can be achieved only when the data are stored permanently.
Different Grid systems address book-keeping problems differently, but all known solutions involve a central database that stores job records. The difference comes in the technology used to populate the databases, and in the kind of information being stored. So far ATLAS has made no explicit use of the Grid-specific logging and book-keeping services. Instead, accounting and historical analysis relied on the records in the ATLAS production database, filled by the supervisors. This is an adequate approach, with only one major limitation: the production database stores only information about the jobs, hence it is impossible to estimate such parameters as the overall system load, efficiency, share of problematic sites, etc.
By "accounting" we refer to the collection of data on the usage of CPU and storage resources by ATLAS jobs that are submitted through a central system. Other ATLAS jobs may be submitted by ATLAS users directly to the different Grids, but in that case we have no way of knowing what resources have been used.
Accounting has to be performed on two levels, the Grid side and the experiment's. Information must be available from the Grids on all jobs run by each user (or user group), and at the same time we must be able to retrieve easily such information from the production database. This information should allow cross-checks of accounting information.
The proposed separation of active from completed jobs in the production database will also help with the collection of accounting information, as statistics can be accumulated regularly on the completed jobs and stored in other database tables for future reference.
A set of tools to query the database to collect monitoring and accounting information in a uniform way is in preparation. Summary accounting information will be saved for further usage in a persistent structure. Tools for the easy retrieval of the information with web access are also being worked on.
After the end of the current round of productions for the Rome Physics Workshop (June 2005), there will be time to phase in the revised production system and test it during Summer 2005, before the next round of productions starts in late autumn 2005.
The next large-scale productions will see the generation of several tens of millions of events with a more realistic detector geometry (the "as-built" geometry), including misalignment and detector sagging, to be used for tests of trigger code and of the conditions database infrastructure, as well as of alignment and calibration procedures. This production activity is preliminary to the "Computing System Commissioning" operation in the first half of 2006, described in detail in Section 8.2.2 .
| | |
Copyright © CERN 2005