   |  |
Computing Technical Design Report
| | |
Computing Technical Design Report
Input parameters for the offline Computing Model are derived from the information contained in the "HLT/DAQ TDR" [2-4] and the "Physics TDR" [2-5]. All input parameters are to be considered as reference numbers representing our best estimates at the moment. In the following sections, the ATLAS Computing Model is first worked out for one year of steady-state operation of proton-proton data taking. Later chapters deal with the commissioning of the system and the resource requirements as a function of time.
The machine and trigger parameters assumed for the Computing Model are summarized in Table 2-1. It is assumed that the trigger thresholds and selection conditions will be adjusted continually so as to maximize the physics reach of the experiment.
The assumptions of Table 2-2 are used to calculate the storage and computing resources (the definitions of the various data types are given in the next section).
The assumed processing times are projections based on those for the current code, in the light of planned future improvements and known inefficiencies, and are for the running conditions in 2008 and 2009. Between data without pile-up and the pile-up for the design luminosity of 1034 cm-2s-1, the event sizes are seen to grow by 50% and the processing time by 75%; this information is used in the resource evolution projections. At present, all processing-time numbers are higher than assumed here, the reconstruction by a factor of two and the simulation by a factor of about four. For the event sizes, the first prototype of the AOD is about 60% that assumed here (but has yet to be tested in terms of the required functionality for analysis). The other data formats are presently larger than the target size, but the target sizes are believed to be achievable. (For example, the RAW data size is 1.7 MB without pile-up, but twice this size after pile-up at full luminosity.)
The physics event store holds a number of successively derived event representations, beginning with raw or simulated data and progressing through reconstruction into more streamlined event representations suitable for analysis. Constituent components are described in the following paragraphs.
RAW Data: RAW data are events as output by the Event Filter (EF, the final stage of the HLT) for reconstruction. The model assumes an event size of 1.6 MB, arriving at an output rate of 200 Hz (including 20 Hz of calibration trigger data).
Events arrive from the Event Filter in "byte-stream" format, reflecting the format in which data are delivered from the detector, rather than in any object-oriented representation. Events will be transferred from the EF to the Tier-0 in files of at most 2 GB. Each file will contain events belonging to a single run (corresponding to a prolonged period of data taking using the same trigger selections on the same fill in the accelerator), but the events in each file will not be consecutive nor ordered [2-6].
Event Summary Data (ESD): ESD refers to event data written as the output of the reconstruction process. ESD is intermediate in size between RAW and Analysis Object Data (see below). Its content is intended to make access to RAW data unnecessary for most physics applications other than for some calibration or re-reconstruction. ESD has an object-oriented representation, and is stored in POOL ROOT files. The target size is 500 kB per event [2-7].
Analysis Object Data (AOD): AOD is a reduced event representation, derived from ESD, suitable for analysis. It contains physics objects and other elements of analysis interest. The target size is 100 kB per event. It has an object-oriented representation, and is stored in POOL ROOT files.
Tag Data (TAG): TAG data are event-level metadata -- thumbnail information about events to support efficient identification and selection of events of interest to a given analysis. To facilitate queries for event selection, TAG data are stored in a relational database. The assumed average size is 1 kB per event.
Derived Physics Data (DPD): DPD is an n-tuple-style representation of event data for end-user analysis and histogramming. The inclusion of DPD in the Computing Model is an acknowledgment of the common practice by physicists of building subsamples in a format suitable for direct analysis and display by means of standard analysis tools (PAW, ROOT, JAS etc.), though software providers certainly expect that analysis, histogramming, and display via standard tools will be possible with AOD as input.
Simulated Event Data (SIM): SIM refers to a range of data types, beginning with generator events (e.g. from Pythia or similar programs) through simulation of interactions with the detector (e.g. Geant4 hits) and of detector response (digitization). It may also include pile-up, with the superposition of minimum bias events, or the simulation of cavern background. Events may be stored after any of these processing stages. The storage technology of choice is POOL ROOT files. Digitized events may alternatively be stored in byte-stream format for trigger studies or for emulation of data coming from the Event Filter. Simulated events are often somewhat larger than RAW events (approximately 2 MB in size), in part because they usually retain Monte Carlo "truth" information.
Other formats are allowed in the software and processing model that are not included in the baseline. For example, the Derived Reconstruction Data (DRD) is an option being considered for the early phase of data taking for a subset of the data. It consists of raw data augmented with partially reconstructed objects to allow easy calibration and optimization of detector code. This format is only of use if the trade-off between storage cost and CPU to derive the partial-reconstruction is in the favour of storage. This in turn depends on the sample size required and the number of times the sample is passed-over by the detector groups.
While the ATLAS Computing Model is very much Grid-based, there still remain distinct roles for different facilities that may be characterized in the following ways. It is to be stressed that all are important and make an invaluable contribution to ATLAS, and a sensible balance between the resources in the various Tiers is essential for the operation of the Computing Model. A guiding principle is to ensure two backed-up copies of the main data formats are made, giving security against failures.
The Tier-0 facility at CERN is responsible for the archiving and distribution of the primary RAW data received from the Event Filter. It provides the prompt reconstruction of the calibration and express streams and the somewhat slower first-pass processing of the primary event stream. The derived datasets (ESD, primary AOD and TAG sets) are distributed from the Tier-0 to the Tier-1 facilities described below, and the reconstructed calibration data to the CERN Analysis Facility for data-intensive calibration. More automated calibration tasks will also be run by the Tier-0.
The Tier-0 must provide an extremely high availability and response time in the case of errors. In the event of prolonged down-time, first-pass processing and calibration must be taken over by the Tier-1 facilities described below. To account for failures and network outages, a disk buffer corresponding to about 5 days of data production will be required for the data flowing into the Tier-0. A smaller output buffer will be required in case of failures in the transfer of the derived datasets offsite (although switching to an alternate Tier-1 destination must be possible in the system).
Access to the Tier-0 facility is granted only to people in the central production group and those providing the first-pass calibration.
Approximately 10 Tier-1 facilities are planned world-wide that will serve ATLAS. They take responsibility to host and provide long-term access and archiving of a subset of the RAW data (on average 1/10th each). They also undertake to provide the capacity to perform the reprocessing of the RAW data under their curation, and to provide ATLAS-wide access to the derived ESD, AOD and TAG datasets, with the most up-to-date version of the data available with short latency (`on disk') and the previous version available but perhaps with a longer latency (`on tape'). The Tier-1s also undertake to host a secondary low-latency copy of the current ESD, AOD and TAG samples from another Tier-1, and the simulated data samples from Tier-2 facilities to improve access and provide fail-over. All of the datasets hosted are considered to be for the collaboration as a whole, and the storage and CPU pledged to be funded by the Tier-1 for that purpose.
The Tier-1s must allow access to and provide capacity to analyse all of the hosted samples, and will provide part of the calibration processing capacity. Modest RAW data samples must be available at short latency to allow calibration and algorithmic development. They will also host some of the physics-working-group DPD samples.
Tier-1 facilities are expected to have a high level of service in terms of availability and response time. Given the vital role in receiving the raw data and reprocessing, down-times in excess of 12 hours become problematic in terms of catching up with processing and with the storage elsewhere of RAW data. The fact that the ESD will be copied to two sites (see Section 2.2.5 ) reduces somewhat the reliance on a given Tier-1 for short periods.
Access to the Tier-1 facilities is essentially restricted to the production managers of the working groups and to the central production group for reprocessing.
Tier-2 facilities may take a range of significant roles in ATLAS such as providing calibration constants, simulation and analysis. This range of roles will result in different sizes of the facilities. Tier-2 facilities also provide analysis capacity for physics working groups and subgroups. This analysis activity is generally chaotic in nature. They typically will host one third of the available current primary AOD and the full TAG samples. They will also host some of the physics group DPD samples, most likely in accordance with local interest. In addition, they will provide all of the required simulation capacity for the experiment (but with the simulated data typically migrated to the Tier-1 unless general on-demand access can be ensured at the site). Agreements on the primary host for the data from a given Tier-2 will be negotiated, although some flexibility will be required in the case of access problems. The relationships formed will be influenced by the ATLAS organizational plans and by the networking topology available. The primary host arrangement will help the planning of network links and may well follow the arrangements within a region for Grid operations and user support.
The Tier-2s will also host modest samples of RAW and ESD data for code development. Some Tier-2s may take significant role in calibration following the local detector interests and involvements. It is assumed that the typical users do not require back-navigation from AOD to ESD and beyond in most cases. When they do, it is further assumed that data-placement tools move the required (small) sample of ESD events to the same storage location as the AOD events. (Similar considerations apply if RAW data access is required.) In the case that larger samples need to be processed, it is planned that this would be done on the Tier-1 facilities by someone with production rights and with the agreement of the appropriate working group. The CERN Tier-1 Analysis Facility (see below) is also intended for tasks requiring larger than normal access to the ESD and RAW, and would be used within quotas by individual working-group members.
The level of service in terms of availability and response time expected of a Tier-2 is lower than for a Tier-1 (unless it chooses to host the simulated data it generates).
In principle, all members of the ATLAS virtual organization have access to a given Tier-2. In practice (and for operational optimization), heightened access to CPU and resources may be given to specific working groups at a particular site, according to a local policy agreed with the ATLAS central administration in a way that the ATLAS global policy is enforced over the aggregate of all sites. An example may be that DPD for the Higgs working group may be replicated to a subset of Tier-2 facilities, and the working-group members have heightened access to those facilities.
The CERN analysis facility is, as the name suggests, primarily devoted to analysis, supporting a relatively large user community. It will also provide an important platform for calibration and code development. It will be particularly useful for user access to RAW data, given its co-location with the Tier-0 facility.
The CERN analysis facility is expected to have a level of service comparable to the Tier-0, given its key role in calibration and alignment and the requirement that these activities introduce minimal latency in the first-pass data processing. It is intended to be available to all members of the ATLAS virtual organization, but with priority to people with well defined roles in algorithmic development, calibration and alignment.
There will be a continuing need for local resources within an institution to store user ntuple-equivalents and allow work to proceed off the Grid. Clearly, the user expectations will grow for these facilities, and a site would already provide typically terabytes of storage for local use. Such `Tier-3' facilities (which may be collections of desktops machines or local institute clusters) should be Grid-enabled, both to allow job submission and retrieval from the Grid, and to permit resources to be used temporarily and with agreement as part of the Tier-2 activities. Such resources may be useful for simulation or for the collective analysis of datasets shared with a working group for some of the time.
The size of Tier-3 resources will depend on the local user community size and other factors, such as any specific software development or analysis activity foreseen in a given institute, and are therefore neither centrally planned nor controlled. It is nevertheless assumed that every active user will need O(1 TB) of local disk storage and a few kSI2k of CPU capacity to efficiently analyse ATLAS data.
The source of the input real data for the Computing Model is primarily the Event Filter (EF). Data passing directly from the online to offsite facilities for monitoring and calibration purposes will be discussed only briefly, as they have little impact on the total resources required, and are being studied. While the possibility of other locations for part of the EF is retained, the baseline assumption is that the EF resides at the ATLAS pit. Other arrangements have little impact on the Computing Model except on the network requirements from the ATLAS pit area. The input data to the EF will require approximately 10x10 Gb/s links with very high reliability. The output data requires an average 320 MB/s (3 Gb/s) link connecting it to the first-pass processing facility. Remote event filtering would require upwards of 10 Gb/s to the remote site, the precise bandwidth depending on the fraction of the Event Filter load migrated away from the ATLAS pit.
While the option of `streaming data' at the EF should be retained, the baseline model assumes a single primary stream containing all physics events flowing from the Event Filter to Tier-0. Several other auxiliary streams are also planned, the most important of which is a calibration hot-line containing calibration trigger events (which would most likely include certain physics event classes). This stream is required to produce calibrations of sufficient quality to allow a useful first-pass processing of the main stream with minimum latency. A working target (which remains to be shown to be achievable) is to process 50% of the data within 8 hours and 90% within 24 hours.
Two other auxiliary streams are planned. The first is an express-line of physics triggers containing about 5% of the full data rate. These will allow both the tuning of physics and detector algorithms and also a rapid alert on some high-profile physics triggers. It is to be stressed that any physics based on this stream must be validated with the `standard' versions of the events in the primary physics stream. However, such a hot-line should lead to improved reconstruction. It is intended to make much of the early raw-data access in the model point to this and the calibration streams. The fractional rate of the express stream will vary with time, and will be discussed in the context of the commissioning.
The other auxiliary stream contains pathological events, for instance those that fail in the event filter. These may pass the standard Tier-0 processing, but if not they will attract the attention of the development team. They will be strongly rate-limited.
The following assumptions are made about output from the Event Filter and input to first-pass reconstruction:
Note that this process does not ensure that the events within a file are time ordered. The following steps occur when raw data arrives at the input-disk buffer of the first-pass processing facility (henceforth known as Tier-0):
Step 2, the transfer of the RAW data to external Tier-1 facilities, is an important requirement. These sites are the primary data sources for any later re-reconstruction of that data, and serve as the principal sources of CPU resources for any such reprocessing. It not only allows reprocessing of data, asynchronous with data taking, it also allows additional capacity to be employed if there is a backlog of first-pass processing at the Tier-0. Note that this implies a degree of control over the Tier-1 environment and processing that is comparable to that at the Tier-0.
Selected ESD will also be copied to Tier-2 sites for specialized purposes. Resource estimates reflect this fact, but the models and policies by which this replication may be accomplished are negotiated among Tier-1 centres and their associated Tier-2 sites.
The AOD and TAG distribution models are similar, but employ different replication infrastructure because TAG data are database-resident. AOD and TAG distribution from CERN occur upon completion of first-pass reconstruction processing of each run.
An output rate of 200 Hz is approximately 4 Hz per SFO. At 1.6 MB per event, each SFO will fill a 2GB file with approximately 1250 events every 5 minutes. This in itself sets a minimum time before processing can proceed for any stream. However, this merely sets the latency for the `prompt' reconstruction; for the primary stream, the latencies will be set by the time until calibration, alignment, and other conditions data are available to Tier-0 processors as discussed in Section 2.5.3 . Data arrives at the Tier-0 at a rate of 320 MB/s. A disk pool requires approximately 25 TB for each day of buffer capacity it is proposed to provide. Proposed criteria for overall production latency are:
The system is assumed to have an input disk buffer of 127 TB, which corresponds to approximately five days of data taking.
The processing of the calibration and alignment data, which crucially sets the latency for the bulk processing, is discussed in Section 2.5 .
It should be noted that the first-pass processing provides the opportunity for more sophisticated filtering and compression/data reduction of the RAW data sample. As confidence is gained with the processing chain and the understanding of the detector, this may be taken advantage of to reduce the RAW data stored at the remote sites (and consequently the volume of derived data). However, for the baseline model we do not assume such a reduction. In the baseline model, the RAW data distributed to the Tier-1s is a straight copy of the data received from the Event Filter, and will often be shipped offsite before the first-pass processing has occurred.
First-pass ESD production takes place at the Tier-0 centre. The unit of ESD production is the run, as defined by the ATLAS data acquisition system. ESD production begins as soon as RAW data files and appropriate calibration and conditions data arrive at the Tier-0 centre. The Tier-0 centre provides processing resources sufficient to reconstruct events at the rate at which they arrive from the Event Filter. These resources are dedicated to ATLAS event reconstruction during periods of data taking. The current estimate of the CPU required is 3000 kSI2k (approximately 15 kSI2k-seconds per event times 200 events/second). It is assumed that in normal operations all first-pass processing is conducted on the CERN Tier-0 facility, although the Tier-1 facilities could provide additional capacity in exceptional circumstances.
A new job is launched for each RAW data file arriving at the Tier-0 centre. Each ESD production job takes a single RAW event data file in byte-stream format as input and produces a single file of reconstructed events in a POOL ROOT file as output. With the current projection of 500 kB per event in the Event Summary Data (ESD), a 2 GB input file of 1250 1.6 MB RAW events yields a 625 MB output file of reconstructed (ESD) events as output.
Production of Analysis Object Data (AOD) from ESD is a lightweight process in terms of CPU resources, extracting and deriving physics information from the bulk output of reconstruction (ESD) for use in analysis. An AOD production job in principle takes one or more ESD files in POOL ROOT format as input, and produces one or more POOL ROOT files containing AOD as output. Current estimates suggest an AOD size of 100 kB per event.
AOD must be derivable from ESD without reference to RAW data, but one might imagine concatenating RAW+ESD+AOD production into a single job for the sake of efficiency. While the database and control framework infrastructure support such concatenation, the current model separates ESD from AOD production. The reason is that job concatenation results in a large number of small files: a concatenated job that takes a single 2 GB RAW event file as input, while producing a 625 MB ESD file, would produce only a 125 MB AOD file, even if only one output AOD stream is written. If AOD output is written to multiple streams, AOD files are likely to average approximately 12 MB in size. The proposed model for first-pass AOD production is therefore to run it as a separate step at the Tier-0 centre, using on the order of 50 ESD files as input to each AOD production job.
As AOD events will be read many times more often than ESD and RAW data, AOD events are physically clustered on output by trigger or physics channel or other criteria that reflect analysis access patterns. This means that an AOD production job, unlike an ESD production job, produces many output files. The baseline streaming model is that each AOD event is written to exactly one stream: AOD output streams comprise a disjoint partition of the run. All streams produced in first-pass reconstruction share the same definition of AOD. On the order of 10 streams are anticipated in first-pass reconstruction.
It is of course true that some events are of interest to more than one physics working group. Such events are nonetheless written only once, to avoid complications for analyses that cross stream boundaries (e.g., "Have I already seen this event in another stream?"). Streams should be thought of as heuristically-based data access optimizations: the idea is to try to reduce the number of files that need to be touched in an average analysis, not to produce perfect samples for every analysis. More specialized sample building will take place at Tier-1 and Tier-2 centres. Every Tier-1 centre receives a complete copy of the AOD -- all of the streams. The streams merely control which events are close to which other events in which files.
AOD production jobs simultaneously write event-level metadata (event TAGs), along with "pointers" to POOL file-resident event data, for later import into relational databases. The purpose of such event collections is to support event selection (both within and across streams), and later direct navigation to exactly the events that satisfy a predicate (e.g., a cut) on TAG attributes.
To avoid concurrency control issues during first-pass reconstruction, TAGs are written by AOD production jobs to files as POOL "explicit collections," rather than directly to a relational database. These file-resident collections from the many AOD production jobs involved in first-pass run reconstruction are subsequently concatenated and imported into relational tables that may be indexed to support query processing in less than linear time.
While each event is written to exactly one AOD stream, references to the event and corresponding event-level metadata may be written to more than one TAG collection. In this manner, physics working groups may, for example, build collections of references to events corresponding to (possibly overlapping) samples of interest, without writing event data multiple times. A master collection ("all events") will serve as a global TAG database. Collections corresponding to the AOD streams, but also collections that span stream boundaries, will be built during first-pass reconstruction.
Standard utilities provided by the database group make it possible to analyse the events in such collections by following the pointers to the corresponding events at sites that host the corresponding event data (e.g., all Tier-1 sites for AOD), or, alternatively, to run extraction jobs that iterate over all events in such a collection and extract (copy) the corresponding data into personal files that contain those events and no others, perhaps for shipment to smaller-scale facilities or personal computers. Such extraction is expected to be common at Tier-1 and Tier-2 sites.
Alternate models have been considered, and could also be viable. It is clear from the experience of the TeVatron experiments that a unique solution is not immediately evident. The above scenario reflects the best current understanding of a viable scheme, taking into account the extra constraints of the considerably larger ATLAS dataset. It relies heavily on the use of event collections and the TAG system. These methods are only undergoing their first serious tests at the time of writing. However, the system being devised is flexible, and can (within limits) sustain somewhat earlier event streaming and modestly overlapping streams without drastic technical or resource implications.
The current model assumes that the new data will be reprocessed approximately 2-3 months after acquisition using the same software version but improved calibration and alignments. These will be obtained from continued study of the calibration stream data and also of the first-pass ESD. It is this `offline' calibration process that sets the time scale for the reprocessing. A second reprocessing of the complete dataset, including the data from previous years, is envisaged at the end of data taking each year, using up-to-date algorithms and calibrations. The reprocessing will probably take place more frequently during the first couple years. In some cases it may be possible to reprocess starting from ESD rather than going back to the raw data.
It is assumed that the bulk reprocessing occurs at the Tier-1 facilities, and that the dominant access to RAW data will be through this scheduled and read-occasionally process. It is possible that the EF farm could be pressed into service for this activity; we believe that the architecture of the Tier-0 and EF farms should allow the repartitioning of resources between the two. However, such dual use is not assumed in the baseline Computing Model.
| | |
Copyright © CERN 2005
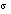
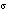 = 109 Hz p-p collisions at design luminosity
= 109 Hz p-p collisions at design luminosity