   |  |
Computing Technical Design Report
| | |
Computing Technical Design Report
As stated in the Computing Model, the Tier-0 facility at CERN is responsible for the following operations:
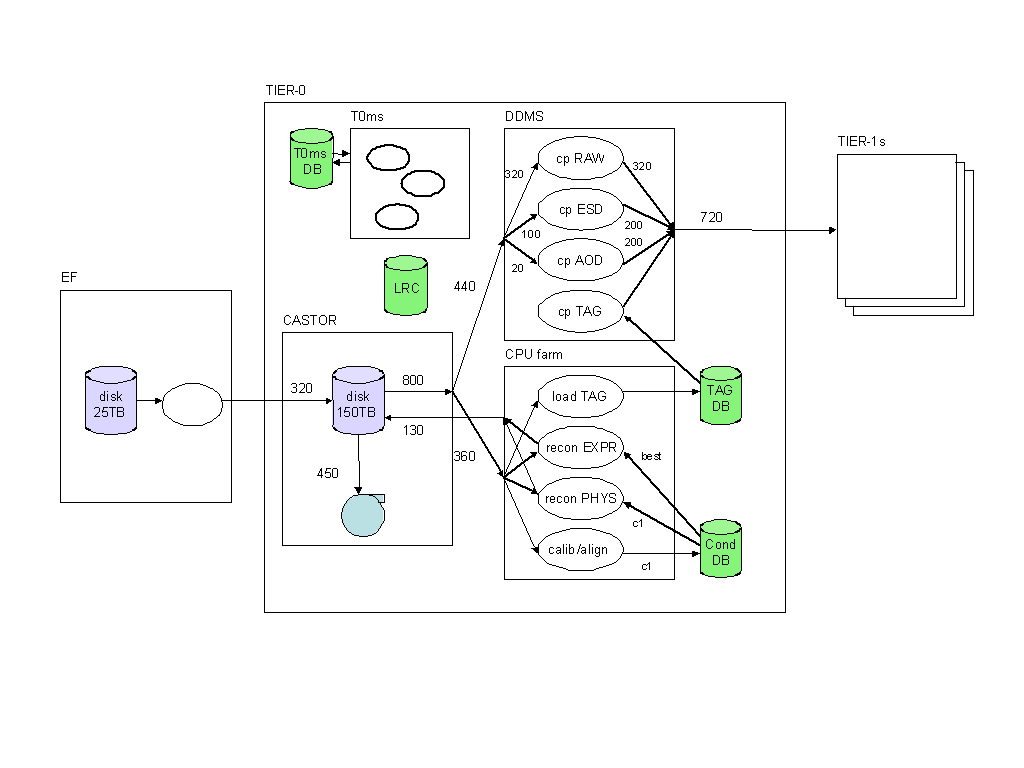
Figure 6-1 shows a diagram of the proposed high-level organization of the Tier-0. RAW data enters the Tier-0 from the Event Filter (EF) at a rate of 320 MB/s. This data consists of four streams: the main physics stream and the smaller streams of calibration/alignment events (45 MB/s), the express stream (~6 MB/s), and the much smaller stream of pathological events. RAW, ESD, AOD and TAG data are copied out of the Tier-0 to the Tier-1s at a rate of ~720 MB/s. The Tier-0 itself consists of several components:
|
The main storage facility is the Castor hierarchical mass storage system. This system will provide the necessary disk space for both the input buffer (125 TB, corresponding to 5 days of data-taking) and the output buffer (25 TB, or 2 days). A process running in the EF system will transfer the RAW files from the EF output buffer into this Castor component. The first-pass reconstruction processes will read their RAW input and write their ESD, AOD and TAG output onto this disk space. The Castor migrator will copy all files to tape as soon as possible with an average writing speed of 440 MB/s (320 RAW + 100 ESD + 20 AOD + 0.2 TAG).
Unless the processes reading the Castor data are stalled for a very long time (several days), all files will be used before being purged from the disks and recall from tape will not be necessary. In the very unlikely case that such a big backlog is built up, care will be taken that processing it does not interfere with real-time processing, ensuring that no new backlog is created.
The main computing resource is the Tier-0 reconstruction farm. All jobs processing the physics and the express RAW data files into ESD, AOD and TAG data files run on this farm. In addition, the jobs processing the calibration and alignment RAW stream into conditions records in the conditions DB and the jobs uploading the TAG files into the TAG DB will be run on this CPU farm.
The distribution of the Tier-0 data products to the Tier-1s will be handled by a dedicated instance of the ATLAS distributed data management system (DDMS). The DDMS will provide the service accepting file movement requests and ensuring that these requests are eventually executed. The DDMS interacts with the Castor component through its gridftp interface and expects a local replica catalogue to be duly filled with entries for all the files stored on the Castor system.
The final component is the Tier-0 management system (T0MS) that will orchestrate the Tier-0 operation. This system has to define and execute jobs on the reconstruction farm and fill the DDMS with transfer requests. In that respect it is very similar to the ATLAS production system and indeed current expectations are that it will be built upon this production system.
There is one important difference: Tier-0 operation is largely data-driven while the production system is largely job-driven. Additional logic will be needed to translate the events of file creations into the appropriate job definitions.
Not all runs will be of equal length and not all files will be filled up to the same amount of events. This poses little complication for the jobs processing a single input file into a single output file, but it will require some attention for the jobs processing multiple input files.
Splitting the AOD generation from the ESD generation allows one to produce fewer and larger AOD/TAG files, but at the expense of reading the input ESD again from disk, thus adding an additional 100 MB/s to the reading rate of the Castor component.
Alternatively one could produce ESD and AOD in one job and merge the resulting small AOD files instead. This scheme naturally allows merging the different AOD channels with different group sizes compensating for any (very likely) imbalance between the channels. The intermediate small AOD files could then be discarded. This scenario would only create an additional 20 MB/s reading load on the Castor component.
It is expected that initially, and probably always, a human intervention will be needed to verify the results of the calibration and alignment processing. No physics RAW processing should start until after this "green light". The physical implementation of this "green light" can be the act of tagging the data in the conditions database.
Given that the Tier-0 will be data-driven, the question arises of how data appearance will trigger actions. The simplest and most robust solution is probably to just periodically check the catalogue(s) for new data. In case, for some reason, this scheme is too naive, one could envisage a simple messaging system based on a message database.
The state of the T0MS is persistified in the Tier-0 production database and will probably be an extension of the state of the ATLAS production system. In the event of a T0MS crash, a restart from the T0MS DB should be possible with close to zero loss of information
On the EF side this means that data will enter the EF output buffer faster than they can be moved to Castor. A backlog will build up in the EF output buffer at a rate of (1 - efficiency) x 320 MB/s. Eventually the EF output buffer will become full and data will be lost. Because the expected average data taking time per day is only 50k seconds (~60%), we expect that even a one-day backlog can be compensated for within the order of one week of operation.
For the distribution process to the Tier-1s this means that a backlog will build up inside Castor. Data will not be lost but may eventually be purged from disk and hence need an expensive tape recall when needed later on. For the reconstruction and calibration jobs running on the CPU farm, the implications are that staging in and out of files will slow down and consequently the overall job rate will decrease. Note that this slowdown causes a corresponding slowdown of output file creation and hence will certainly not aggravate the situation.
Eventually (after 5/(1 - efficiency) days) all files on disk will be in need of migration to tape. Two possibilities exist now. Strategy one will purge the files from disk anyway to make room for the new arriving files. Most likely, most files in the mean time will have already been distributed to the Tier-1 centres and hence could be recovered from there. So, this strategy requires some minimal coordination between the purging process and the distribution process to ensure that files that are indeed replicated out already are purged first. In addition, an asynchronous recovery process could attempt to recover the lost primary tape copies from the Tier-1 centres when spare bandwidth is available. Strategy two will not purge non-migrated files from disk and hence will stop input into Castor. The consequences of this are explained above.
The consequences of this are that RAW data enter the Tier-0 faster than they can be processed. The Castor disk will fill up with unprocessed RAW data files and eventually (after 5/ (1 - efficiency) days) RAW files will be purged from disk. Processing these files later on, when the CPU capacity is restored or the RAW inflow has decreased sufficiently, will require an expensive recall from tape. Care should be taken that the processing of these purged RAW files does not decrease the overall CPU farm efficiency to the point that more unprocessed RAW files are purged then recovered. A zero-th order strategy ensuring this, is to process files that need tape recall only when no other files can be processed.
The consequences of this are that data (RAW, ESD, AOD) enter Castor faster than they can be distributed to the Tier-1s. The Castor disk will fill up with undistributed data files and eventually (after 5/ (1 - efficiency) days) files will be purged from disk. Distributing these files later on, when the bandwidth is restored, will require an expensive recall from tape. Care should be taken that the recall of these purged files does not decrease the overall Castor efficiency to the point that more problems are caused than solved. Tape recall could, for example, destructively interfere with the migration to tape.
Here we need to distinguish between the three different distribution strategies for RAW, ESD and AOD.
For RAW, on average, one tenth of the data will be distributed to one of the 10 Tier-1s. In case of bandwidth problems to this Tier-1, one can either decide to distribute it to another Tier-1 instead, or stall the distribution until the bandwidth is restored. Strategy one requires an additional component monitoring the distribution and dynamically redirecting the scheduled transfers. Strategy two has the same consequences with respect to tape recalls as the previous scenario.
ESD needs to be distributed to two Tier-1 centres, so it is in fact equivalent to two times the RAW situation.
AOD needs to be replicated to all Tier-1 centres, so a strategy redirecting the copy cannot be applied.
Given that the Tier-1 centres are supposed to have a very high level of availability, current thinking is that it will be sufficient to simply stall the transfers and not enable dynamic redirection.
As the loading of the TAG database from the TAG files is asynchronous with respect to the other processing anyway, in the worst case the TAG files could be purged from disk before they are used. Given the huge size of the Castor buffer and the small size of the TAG files, even the latter seems close to impossible. A little bit of care must be taken so that not all or even a small fraction of CPUs are occupied with TAG loading jobs waiting for the TAG database.
No or degraded Conditions DB response will stop, crash, or slow down all jobs running on the CPU farm, and hence have the same effect as scenario 5. In this respect it would be advantageous for reconstruction jobs to access the conditions database in a concentrated way at start-up rather than continuously; in any case, all events in a single RAW data file are produced within at most a few minutes and with the same trigger conditions.
A crash of the Tier-0 management system will cause no new actions to be initiated. Most importantly, no new jobs will be submitted to the CPU farm. With an average job length of several hours, a simple (automatic) reboot within O(10) minutes would probably already suffice. In addition, like the multiple supervisor set-up in the ATLAS production system, one could envisage running multiple collaborating instances of the T0MS.
Calibration and alignment processing refers to the processes that generate "non-event" data that are needed for the reconstruction of ATLAS event data. These non-event data are generally produced by processing some raw data from one or more sub-detectors, rather than being raw data themselves. The input raw data can be in the event stream (either normal physics events or special calibration triggers) or can be processed directly in the sub-detector readout systems. The output calibration and alignment data will be stored in the conditions database.
At the moment it has not yet been decided whether all the calibration processing will run as a single job or be split in the event dimension and/or per detector. In any case it is certain that at least some results will depend upon data spread over the complete run, and hence cannot be computed until the complete run is available. In that respect, it may be of limited usefulness to introduce the complication of starting part of the calibration processing before a run is completed.
Calibration and alignment activities will also occur elsewhere, notably at the CERN Analysis Facility. These will be different, being more developmental in nature, intensive in human effort and not automatic. The time-scales involved will typically be longer, and will influence the latency of the reprocessing of the data, not the first processing at the Tier-0.
First-pass ESD production takes place at the Tier-0 centre. The unit of ESD production is the run, as defined by the ATLAS data acquisition system. ESD production begins as soon as RAW data files and appropriate calibration and conditions data are available. The Tier-0 centre provides processing resources sufficient to reconstruct events at the rate at which they arrive from the Event Filter. These resources are dedicated to ATLAS event reconstruction during periods of data taking. The current estimate of the CPU power required is 3000 kSI2k (approximately 15 kSI2k-seconds per event times 200 events/second).
Note that this is the capacity needed to keep up with the RAW data in real time. It is expected that on average only 50k seconds per day data will effectively be taken, so on average only ~60% of this capacity is needed. However, as data-taking periods may be distributed unevenly and as occasionally backlogs will need to be caught up with, the remaining 40% has to be kept as a safety margin.
A new job is launched for each RAW data file arriving at the Tier-0 centre. Each ESD production job takes a single RAW event data file in byte-stream format as input and produces a single file of reconstructed events in a POOL ROOT file as output. With the current projection of 500 kB per event in the Event Summary Data (ESD), a 2-GB input file of 1250 1.6-MB RAW events yields a 625-MB file of ESD events as output.
Production of Analysis Object Data (AOD) from ESD is a lightweight process in terms of CPU resources, extracting and deriving physics information from the bulk output of reconstruction (ESD) for use in analysis. Current estimates propose a total AOD size of 100 kilobytes per event.
As AOD events will be read many times more often than ESD and RAW data, and analysis access patterns will usually read all AOD of all events belonging to this or that physics channel, it makes sense to physically group the AOD events into streams reflecting these access patterns. Of course, there are many physics channels and many sensible groupings. Satisfying all of them would lead to an excessive number of streams and most likely duplication of events across streams.
As a compromise we expect the physics community to define of the order of 10 mutually exclusive and maximally balanced streams. All streams produced in first-pass reconstruction share the same definition of AOD. Streams should be thought of as heuristically-based data access optimizations: the idea is to try to reduce the number of files that need to be touched in an average analysis, not to produce perfect samples for every analysis. Note that we expect the actual definition of the 10 streams to evolve over time.
The Computing Model foresees a separation of the AOD production from the ESD production in order to avoid an excessive number of small (10 MB and less) AOD files. A separate AOD building step would read in 50 ESD files and produce 50 times fewer and 50 times bigger AOD files.
The disadvantage of this model is that the ESD data needs re-reading from Castor adding an extra 100 MB/s on the reading bandwidth. Additionally, it does not naturally allow the grouping of AOD streams with even fewer events into bigger groups (i.e. the stream imbalance is preserved).
An alternative strategy would be to produce the 10 AOD files (and the TAG file) per RAW file together with the ESD file in a chained job. The resulting small AOD files could then be merged together per AOD channel, using a per-channel optimal grouping size in a separate merging job. As the total AOD size is only 100 kB, this would cause an increase of only 20 MB/s on the Castor reading bandwidth. The total number of jobs seen by the CPU farm remains the same.
AOD production jobs simultaneously write event-level metadata (event TAGs), along with "pointers" to POOL file-resident event data, for later import into relational databases. The purpose of such event collections is to support event selection (both within and across streams), and later direct navigation to exactly those events that satisfy a predicate (e.g., a cut) on TAG attributes.
To avoid concurrency control issues during first-pass reconstruction, TAGs are written by AOD production jobs to files as POOL "explicit collections," rather than directly to a relational database. These file-resident collections from the many AOD production jobs involved in first-pass run reconstruction are subsequently concatenated and imported into relational tables that may be indexed to support query processing in less than linear time.
While each event is written to exactly one AOD stream, references to the event and corresponding event-level metadata may be written to more than one TAG collection. In this manner, physics working groups may, for example, build collections of references to events corresponding to (possibly overlapping) samples of interest, without writing event data multiple times. A master collection ("all events") will serve as a global TAG database. Collections corresponding to the AOD streams, but also collections that span stream boundaries, will be built during first-pass reconstruction.
RAW data and first-pass ESD, AOD and TAG data will be permanently archived at the Tier-0 with a copy on the Tier1s. For 2008 we estimated (Chapter 7) that we will need 6.2 PBof tape storage at the Tier-0 and of the order of 9.0 PB for all the Tier-1s.
ATLAS decided to use a Distributed Data Management system and has started the development of the final version of that system called DonQuijote-2 (DQ2). Based on the experience gained while running the Data Challenges, the system is fully described in Section 4.6 ; in particular the system has been designed in such a way that a multiplicity of Grids can be supported.
DQ2 will be used for all types of data transfer (RAW, ESD, AOD, TAG, Monte Carlo, etc.), for all possible exchanges between Tiers in any direction. We expect to test the full system in the Service Challenge 3 in Autumn 2005 and have it ready for the computing commissioning scalability tests in early 2006.
As described in the Computing Model, ATLAS Tier-1s will be a set of full-service computing centres for the Collaboration. They will provide a large fraction of the raw and simulation data storage for the experiment. They will also provide the necessary resources to perform reprocessing and analysis of the data.
In accepting to host a copy of the raw data, each Tier-1 also accepts to provide access to this data for the entire collaboration and to provide the computing resources for the reprocessing. It is not expected that access to all of the hosted raw data should be available on a short latency but at least a reasonable fraction of it should be on fast disk storage for calibration and algorithm development. However, access to ESD, AOD and TAG datasets should always be available with short latency (on `disk'), at least for the most recent version of processing, while previous versions will be available with a longer latency (on `tape').
In accepting data from Tier-2, a Tier-1 accepts to store them in a permanent and safe way and to provide access to it in agreement with current ATLAS policy. This is true for both simulated and derived data.
In order to meet these goals a set of services should be provided:
These services should be of high quality in terms of availability and response time.
Each local site will be primarily responsible for its hardware, storage and network services. This will be organized by the Tier-1 board.
The operations at the Tier-1 will be the responsibility of the Computing Operations Group. The production managers of the working groups will be allowed to submit their respective productions in agreement with the general ATLAS production policy.
Full read-write access to Tier-1 facilities will be restricted to the Production Managers of the working groups and to the central production group for reprocessing and overall data management.
It is not excluded that a given Tier-1 provides services to local users beyond its ATLAS Tier-1 role.
Tier-2 facilities will play a range of roles in ATLAS such as providing calibration constants, simulation and analysis. They will provide a flexible resource with large processing power but with a more limited availability compared to a Tier-1 in terms of mass storage accessibility and network connectivity.
In order to meet these requirements, a set of services should be provided. They include:
The simulation production will be the responsibility of the production managers. Analysis or detector studies activities will be the responsibility of the corresponding working groups which should appoint a production manager.
Read access should be provided to all members of the ATLAS VO. Write access should be available to ATLAS Production Managers.
A Tier-2 will have the possibility to request that some specific data should be replicated to it, for example AOD data of interest to the physics community it serves. The request will be sent to the Distributed Management System which will trigger the necessary operations.
In the ATLAS Computing Model, various applications require access to the data resident in relational databases. Examples of these are databases for detector production, detector installation, survey data, detector geometry, online run book-keeping, run conditions, online and offline calibrations and alignments, offline processing configuration and book-keeping.
The Database Project is responsible for ensuring the integration and operation of the full distributed database and data management infrastructure of ATLAS. The Distributed Database Services area of the Project is responsible for the design, implementation, integration, validation, operation and monitoring of all offline database services.
ATLAS data processing will make use of a distributed infrastructure of relational databases in order to access various types of non-event data and event metadata. Distribution, replication, and synchronization of these databases, which are likely to employ more than one database technology, must be supported according to the needs of the various database service client applications. In accordance with the LCG deployment model, we foresee Oracle services deployment in the Tier-0 and Tier-1 centres and MySQL in smaller settings (Tier-2, Tier-3, Tier-4) and for smaller applications.
To achieve the integration goal, ATLAS is developing the Distributed Database Services client library that serves as a unique layer for enforcing policies, following rules, establishing best practices and encoding logic to deliver efficient, secure and reliable database connectivity to applications in a heterogeneous, distributed-database services environment.
ATLAS favours common LHC-wide solutions and is working with the LCG and the other experiments to define and implement common solutions. ATLAS initiated and is actively involved in the LCG distributed database deployment project. ATLAS also initiated and is contributing manpower for the integration of the Distributed Database Services client library functionalities in the Relational Access Layer of the LHC-wide project POOL.
Experience from the deployment of grid technologies in the production environment for ATLAS Data Challenges demonstrated that a naïve view of the grid as a simple peer-to-peer system is inadequate. Our operational experience shows that a single database on top is not enough to effectively run production on a federation of computational grids. Going beyond the existing infrastructure, an emerging hyperinfrastructure of databases complements the Tier-0-Tier-1-...-Tier-N hierarchy of computational grids. The database hyperinfrastructure separates concerns of the local environments of applications running on worker nodes and the global environment of a federation of computational grids. Databases play a dual role: both as a built-in part of the middleware (monitoring, catalogues, etc.) and as a part of the distributed workload management system necessary to run the scatter-gather data processing tasks on the grid. It is the latter role that supplies operations history that is providing data for important `post-mortem' analysis and improvements.
ATLAS has not yet produced a common monitoring tool for all three Grid flavours. Different approaches can be considered to achieve the goal of collaboration-wide monitoring:
Very important information is contained in job exit code. ATLAS Data Challenges demonstrated that it is essential for jobs to return an exit code of high granularity that would simplify production management, facilitate debugging process, and generally help in producing a clear overview of the data processing. On some Grid systems, jobs can get lost, producing no exit code whatsoever, or any other information. A special code range is assigned to such jobs in the book-keeping system. Error reporting can have a finer structure, by also adding error-type code to the information being collected.
Presently, no Grid offers a book-keeping system that is adequate for ATLAS needs. It should be a primary goal of the LCG project to provide a common view on monitoring across the member deployments. In the long term, placing the load for this on the experiment is unsustainable. The solution provided should allow a flexible schema so that the production and individual users can instrument their jobs. Moreover, there are no accepted standards as to what has to be stored as a persistent usage record. The GGF Usage Record Working Group is developing an implementation-independent schema for the resource usage record, suitable for book-keeping purposes. However, even if all the Grids were to adopt this format, it will cover only the most generic information, likely to be insufficient for ATLAS needs. Therefore, information stored in an ATLAS-specific database will remain essential, and it is important to ensure that all the necessary data are collected, reliably stored, and can be easily retrieved.
| | |
Copyright © CERN 2005