Welcome to ArdaGrid Web
More information about wiki, search, preferences, tools: see MoreWikiInformation More on ARDA project and purpose of this page: ArdaGridOur activities
- ARDA homepage: http://cern.ch/arda

- ARDA twiki: https://twiki.cern.ch/twiki/bin/view/ArdaGrid/WebHome
- EIS twiki: https://twiki.cern.ch/twiki/bin/view/LCG/LCGExperimentIntergrationandSupport
- Documents (papers, presentations, etc...)
Ganga
- homepage: http://cern.ch/ganga
- GangaIndex
EnviroGRIDS
- homepage: http://www.envirogrids.net/
AMGA

- homepage: http://cern.ch/amga
- AMGAPracticalNotes for the ACGrid school, Vietnam
UnoSat
- Thesis of Daniel Sandoval Lagrava: https://twiki.cern.ch/twiki/bin/viewfile/ArdaGrid/WebHome?rev=1;filename=thesis.pdf
Grid Reliability
- Site of the day (CMS users; ) - (FireFox and IE only). It provides also the "worker node (or CE) of the day" (CE/worker nodes with error in executing CMS jobs)
- Site of the day ATLAS users
- Site of the day LHCb users
- Site of the day ALICE users
- The 4 VOs T1 of the 4 VOs
- FTS efficiency FTS channel of the day
- Sustained WMS stability monitoring
- Daily WMS performance evaluation and monitoring
- GridReliability (for site managers)
Experiment Dashboard

- ATLAS homepage: http://arda-dashboard.cern.ch/atlas
- CMS homepage: http://arda-dashboard.cern.ch/cms
- ATLAS DDM Monitoring
- Dashboard twiki
- CMS/Dashboard twiki
- Dashboard Project Homepage: http://dashboard.cern.ch
- SiteStatusBoard
ATLAS DDM
- Dashboard Monitoring
VO Specific Service Monitoring
Other Activities
DIANE User Level Scheduling
ITU RRC06: International Telecommunication Union Regional Conference
- ITUConferenceIndex
- ITU page on planning process
- AFS diane.workspace (post-mortem analysis)
- MonaLisa monitoring page
- PreparatoryTests
- OperationProcedures
- PostMortemEvaluation
- ITUPress
- Catalog of official and interesting runs
- Logfile names vs job master ids
Avian Flu Data Challenge
- AvianFluPress
- Statistics of the DIANE runs
- HealthGrid 2006 Poster (PDF)
- HealthGrid 2006 Poster (PPT)
- Presentation on WISDOM workshop@HealthGrid 2006
- Conference paper of NETTAB 2006 (NETTAB 2006, Santa Margherita di Pula, July 10-13, 2006)
- Paper published in IEEE Transaction on Nanobioscience
- EGEE 2006 Demo
Geant4 on the Grid
- Geant4ReleaseTesting
- TestGeant4InstallationBeforeGridDeployment]
- OBSOLETE: RunningGeant4OnTheGrid
- OBSOLETE: Geant4TarballGridInstallation
FUSION/HEP Collaboration (EGEE)
The working directory can be found under: /afs/cern.ch/sw/arda/install/DIANE/FUSIONThe input files (to be included in the InputSandbox) required for each job are: fuentes_lgv.tar.gz and input_lgv.tgz.
In addition a lgv.sh and lgv.jdl files are included into the same directory
The variation of each job can be chosen based on the number of trajectories which can be defined into the file: /inputs/input.lis.tj2. The integration of the 3 following variables: nf*nb*lb provides the number of trajectories.
For about 100 trajectories each job should take about 9-10 min of duration
The granularity of the production is also defined in the same file by the variable: seed (also included in that file). This variable set to zero makes a ramdom evolution of the job cresting therefore different outputs for each job.
Python Testing Framework
Garfield on the Grid
Theoretical Physics
SIXT
Computational Chemistry
ThIS on the Grid
Clouds
AgentFactory
Evaluation of Messaging System for Grids (MSG)
- MSG_Monitoring.odp: Source for "New technologies for Grid Monitoring" presentation
- MSG_Monitoring.pdf: PDF version
NSS2008DemoAndTutorial
Ganga/DIANE Monitoring service
DataTransferForTheoryQCD
LatticeQCDTeraGrid2010
TaskMonitoringWebUI
EGIUserForum2011Training
EGIIntroductoryPackage
Tips and tricks
StudentExperienceInARDA
ARDA Machines
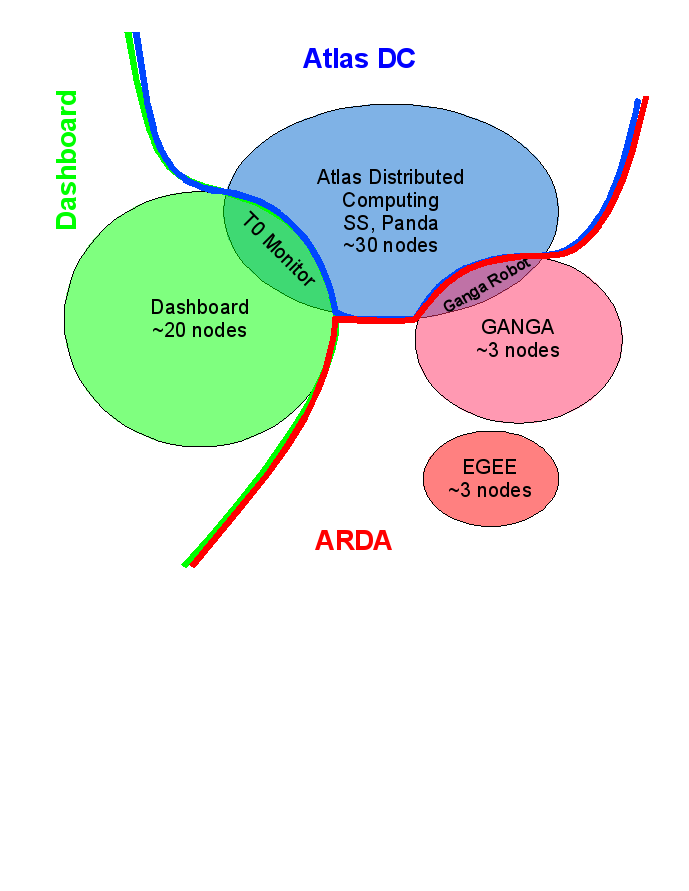
The following gives an overview of the machines we have for ARDA and who is responsible for them.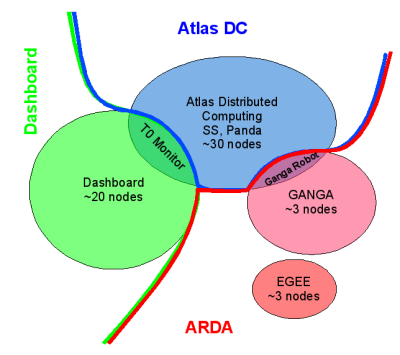 The machines that are in the dashboard cluster are managed by Ricardo Rocha, those in the ARDA and Atlas Distributed Computing Cluster are managed by Birger Koblitz. This means that the following things are done exclusively by the the two:
The machines that are in the dashboard cluster are managed by Ricardo Rocha, those in the ARDA and Atlas Distributed Computing Cluster are managed by Birger Koblitz. This means that the following things are done exclusively by the the two: - hardware requests for new machines in the respective clusters
- Root access, interactive login access


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
C5-July2006-RRC06.ppt | r4 r3 r2 r1 | manage | 2019.0 K | 2006-07-24 - 14:39 | JakubMoscicki | |
| |
EGEE2006_DIANE_AutoDock_DEMO_poster-A2-landscape.ppt | r1 | manage | 3204.0 K | 2006-09-15 - 15:37 | UnknownUser | EGEE 2006 Demonstration Poster |
| |
EGEE_Biomed_DC2_NETTAB2006_v3.pdf | r1 | manage | 246.0 K | 2006-06-22 - 17:21 | HurngChunLee | Avian Flu DC conference paper of NETTAB 2006 |
| |
EGEE_GangaDemo_review.ppt | r2 r1 | manage | 12689.5 K | 2006-05-17 - 18:44 | MassimoLamanna | |
| |
Grid-enabled_high_throughput_in_silico_Screening_against_Influenza_A_Neuraminidases.pdf | r1 | manage | 364.7 K | 2006-09-15 - 15:42 | UnknownUser | Paper for IEEE Transaction on NanoBioscience |
| |
HealthGrid2006_WISDOM_hclee.ppt | r1 | manage | 3750.5 K | 2006-06-20 - 00:57 | HurngChunLee | HealthGrid 2006 WISDOM workshop presentation |
| |
ITU_presentationV7.pdf | r1 | manage | 1160.5 K | 2006-06-15 - 16:54 | MassimoLamanna | |
| |
MSG_Monitoring.odp | r1 | manage | 1417.5 K | 2009-07-09 - 14:01 | MaciejWos | Source for "New technologies for Grid Monitoring" presentation |
| |
MSG_Monitoring.pdf | r1 | manage | 345.2 K | 2009-07-09 - 14:00 | MaciejWos | PDF version of the "New technologies for Grid Monitoring" presentation |
| |
amgalogosml_bg_half.png | r1 | manage | 14.5 K | 2008-08-18 - 17:46 | BirgerKoblitz | |
| |
clusters.png | r2 r1 | manage | 41.1 K | 2008-08-18 - 17:37 | BirgerKoblitz | Distribution of machines in different clusters |
| |
genericlrg.png | r1 | manage | 15.2 K | 2007-11-05 - 16:38 | RicardoRocha | |
| |
healthgrid2006_poster-DIANE-A0-portrait.ppt | r1 | manage | 6916.0 K | 2006-09-15 - 15:39 | UnknownUser | |
| |
healthgrid2006_poster-DIANE-A4-portrait.pdf | r1 | manage | 1285.2 K | 2006-06-20 - 00:47 | HurngChunLee | Avian Flu DC Poster on HealthGrid 2006 conference |
| |
thesis.pdf | r1 | manage | 1581.9 K | 2007-01-26 - 11:50 | BirgerKoblitz | Daniel's thesis |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Topic revision: r102 - 2013-04-10 - MikeKenyon
- ArdaGrid Web
- ArdaGrid Web Home
- Changes
- Index
- Search
- ABATBEA
- ACPP
- ADCgroup
- AEGIS
- AfricaMap
- AgileInfrastructure
- ALICE
- AliceEbyE
- AliceSPD
- AliceSSD
- AliceTOF
- AliFemto
- ALPHA
- Altair
- ArdaGrid
- ASACUSA
- AthenaFCalTBAna
- Atlas
- AtlasLBNL
- AXIALPET
- CAE
- CALICE
- CDS
- CENF
- CERNSearch
- CLIC
- Cloud
- CloudServices
- CMS
- Controls
- CTA
- CvmFS
- DB
- DefaultWeb
- DESgroup
- DPHEP
- DM-LHC
- DSSGroup
- EGEE
- EgeePtf
- ELFms
- EMI
- ETICS
- FIOgroup
- FlukaTeam
- Frontier
- Gaudi
- GeneratorServices
- GuidesInfo
- HardwareLabs
- HCC
- HEPIX
- ILCBDSColl
- ILCTPC
- IMWG
- Inspire
- IPv6
- IT
- ItCommTeam
- ITCoord
- ITdeptTechForum
- ITDRP
- ITGT
- ITSDC
- LAr
- LCG
- LCGAAWorkbook
- Leade
- LHCAccess
- LHCAtHome
- LHCb
- LHCgas
- LHCONE
- LHCOPN
- LinuxSupport
- Main
- Medipix
- Messaging
- MPGD
- NA49
- NA61
- NA62
- NTOF
- Openlab
- PDBService
- Persistency
- PESgroup
- Plugins
- PSAccess
- PSBUpgrade
- R2Eproject
- RCTF
- RD42
- RFCond12
- RFLowLevel
- ROXIE
- Sandbox
- SocialActivities
- SPI
- SRMDev
- SSM
- Student
- SuperComputing
- Support
- SwfCatalogue
- TMVA
- TOTEM
- TWiki
- UNOSAT
- Virtualization
- VOBox
- WITCH
- XTCA
 |
|
or Ideas, requests, problems regarding TWiki? use Discourse or Send feedback