Why does the LHCb Upgrade need a software trigger?
LHCb has a very peculiar design for a collider experiment. It has to cope with over 25 MHz of bunch crossings involving hard interactions (unlike, for example, ALICE), seeks to have similar efficiencies for hadrons and leptons (unlike, for example, ATLAS or CMS), and should carry out precision measurements of processes from Kaon to Electroweak physics i.e. over almost three orders of magnitude in energy scale (unlike any other recent collider experiment). For these reasons LHCb’s aim is not to keep high efficiency for rare signals (as ATLAS or CMS) or high purity for abundant signals (as BaBar or Belle/Belle-2), but to do both of these things simultaneously, and in a regime where the differences between signal and background are small and indeed one persons’ signal is often someone else’s background.
At its nominal instantaneous luminosity the LHCb experiment will produce around 4 Terabytes of data per second, while only around 10 Gigabytes of data per second can be recorded to permanent storage for physics analysis. This means that LHCb, in common with most other experiments, requires a way to decide which parts of the raw or derived detector information are most interesting for physics analysis and save those, discarding the rest. Such a system is commonly known as a “trigger”. The above-described combination of design goals for the LHCb upgrade means that its trigger must make the full detector information available to the decision-making process at the full LHC collision rate. The original physics justification was based on the following plot from the LHCb Upgrade Letter of Intent
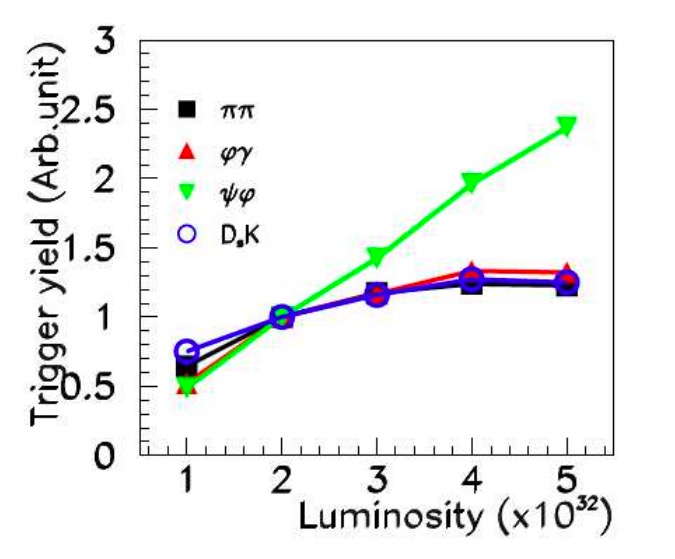
What this plot shows is the triggered signal yield of a selected group of physics channels of interest to LHCb as a function of the instantaneous luminosity at which the experiment operates. The upgrade instantaneous luminosity of 2e33 would lie far off the right-hand-side of this plot. The plot was made assuming that the LHCb Upgrade kept a trigger system whose first stage used only calorimeter and muon information to make decisions, as used by LHCb in Runs 1 and 2. As can be seen, while this is a somewhat viable strategy for selecting muons, it stops being an effective way to select hadrons long before the upgrade instantaneous luminosity. The way to resolve this problem was to make information from the tracking system available already at the first trigger stage. This allows not only particle momenta and energies but also their displacement from the primary proton-proton collisions to be used. That reduces the huge backgrounds from hadrons produced directly in the primary proton-proton collisions and allows the hadronic decays of beauty and charm hadrons to be efficiently selected.
This trigger design is commonly referred to as a “software” trigger, to distinguish it from “hardware” triggers which make their decisions in a fixed time interval (latency) typically based only a subset of detector information. The motivation for the trigger design of the LHCb Upgrade and its dataflow is further discussed in the LHCb Starterkit documentation.
What are the motivations for “real-time analysis” at LHCb?
At the upgrade instantaneous luminosity the LHC produces an average of around 6 proton-proton collisions per bunch crossing, which in turn leads to a typical raw “event” size of around 100 kilobytes per recorded bunch crossing in LHCb. Since the total data volume which can be recorded to permanent storage is around 10 Gigabytes per second it follows that around 100 kHz of full raw LHCb events can be recorded by the trigger. This is however significantly lower than the rate of interesting signals which can be at least partially reconstructed in the LHCb detector, as shown in the following plot
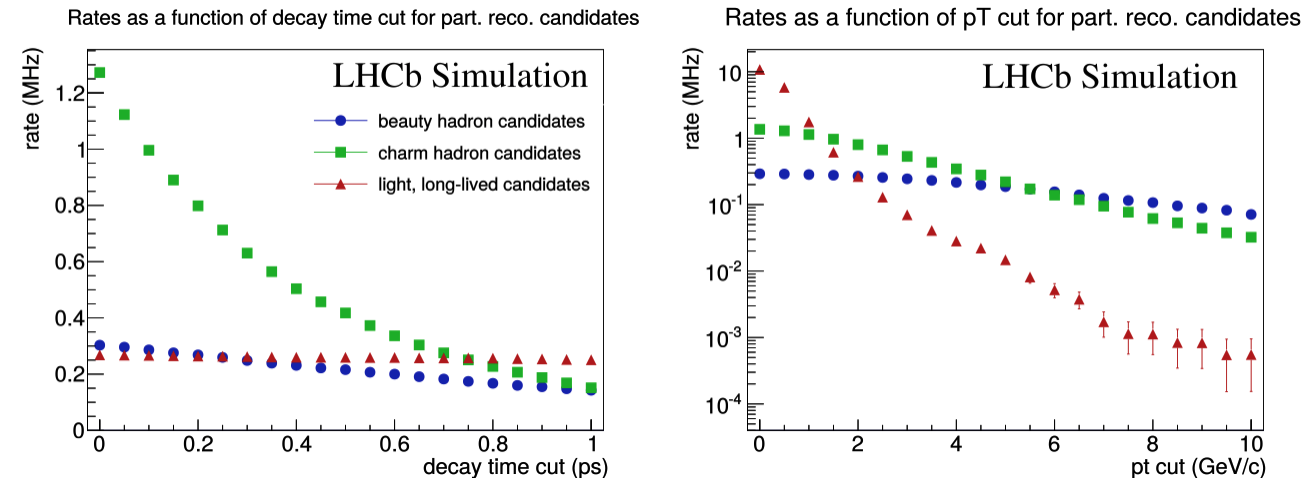
The vast majority of LHCb analyses do not, however, require that the full detector information for every event be kept indefinitely. Because so much of the real-time selection is based on fully reconstructing the signal of interest there is less to be gained by reprocessing the data later, and the resolution of most derived quantities (for example mass or lifetime) can be improved using only information about the signal of interest itself. All the is typically required is therefore a subset of higher-level information about the signal candidate of interest to any specific analysis; about its decay products; about the proton-proton collision from which this candidate originated; as well as some aggregate high-level information about the rest of the event. This information is typically not more than 10 kilobytes per event.
Therefore if it is possible to run the full offline-quality detector reconstruction in real-time, using the full offline-quality detector calibration and alignment, then most of the detector information can be thrown away for the events of interest. This trade-off between selection and compression allows the LHCb Upgrade to record far greater signal yields than would otherwise be possible, in particular for charm and strange physics, and is referred to as “real-time analysis”.
The motivations for real-time analysis are discussed in much more detail in several of the documents linked below as further reading. In particular, physics case studies for real-time analysis in the LHCb Upgrade are discussed in Chapter 4 of the Computing Model document.
Further reading
Letter of Intent for the LHCb Upgrade
Anatomy of an upgrade event in the upgrade era, and implications for the LHCb trigger
LHCb Trigger and Online Upgrade Technical Design Report
Tesla : an application for real-time data analysis in High Energy Physics
A comprehensive real-time analysis model at the LHCb experiment